
StandardScaler is a preprocessing technique provided by Scikit-Learn to standardize features in a dataset. It scales the features to have zero mean and unit variance, which is a common requirement for many machine learning algorithms.
Key Features of StandardScaler
- Centers the data around zero mean.
- Scales the data to have unit variance.
- Does not assume any specific distribution for the features.
- Helps algorithms that are sensitive to feature scales.
When to Use StandardScaler
StandardScaler is particularly useful when features have different scales, and you want to bring them to a common scale to ensure fairness in algorithm performance. It’s beneficial for algorithms like Support Vector Machines, k-Nearest Neighbors, and Principal Component Analysis.
Applying StandardScaler
To use StandardScaler, you simply fit it on your training data and then transform both the training and test data using the learned parameters.
Advantages of StandardScaler
- Improves convergence speed of gradient-based algorithms.
- Enhances the performance of models that rely on distance metrics.
- Provides better visualization of feature distributions.
Considerations and Limitations
While StandardScaler is effective for many cases, it might not work well for data with heavy-tailed distributions or when outliers are present. In such cases, other scaling techniques like RobustScaler or MinMaxScaler could be more appropriate.
Python Code Examples
Example 1: Using StandardScaler on a Dataset
from sklearn.preprocessing import StandardScaler
import numpy as np
# Create a sample dataset
data = np.array([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]])
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit the scaler on the data
scaler.fit(data)
# Transform the data
scaled_data = scaler.transform(data)
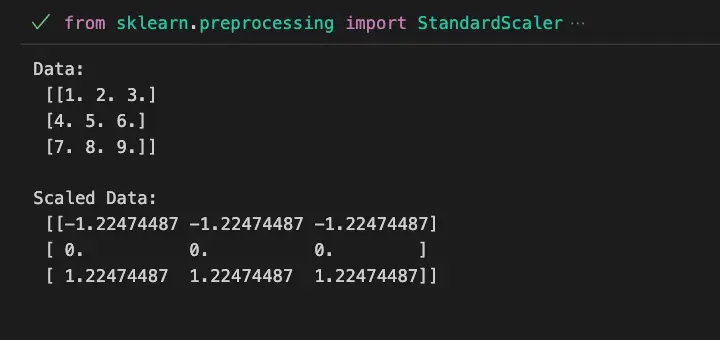
print(f'Data:\n {data}\n')
print(f'Scaled Data:\n {scaled_data}\n')In this example, we create a simple dataset and use StandardScaler to scale the features.
Example 2: Scaling Features for Machine Learning
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# Load the Iris dataset
data = load_iris()
X = data.data
y = data.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and fit StandardScaler on training data
scaler = StandardScaler()
scaler.fit(X_train)
# Transform training and testing data
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# Evaluate the model
accuracy = model.score(X_test_scaled, y_test)
print(f"Accuracy: {accuracy:.2f}")
This example demonstrates how to use StandardScaler in a machine learning pipeline to scale features before training a model.
Visualize Scikit-Learn Preprocessing StandardScaler with Python
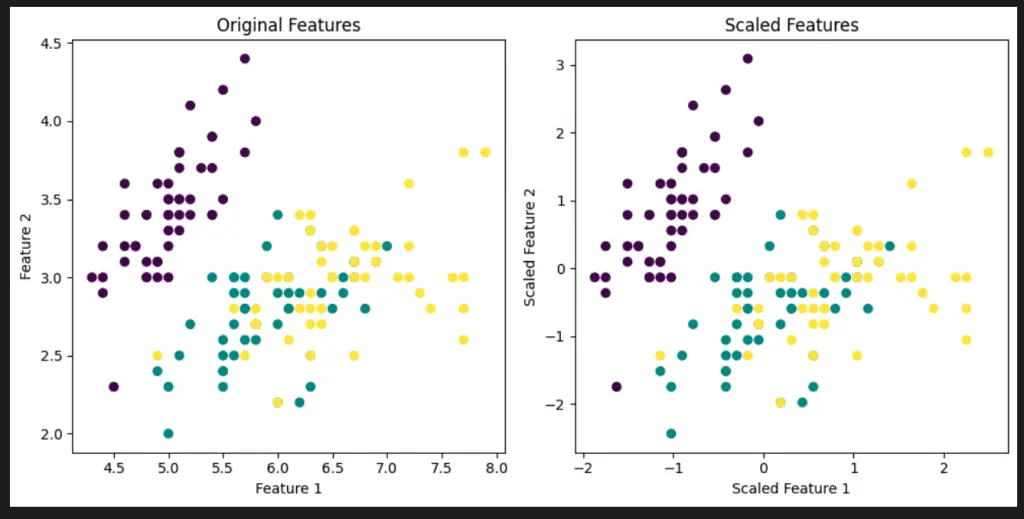
To visualize the effects of using the StandardScaler on a dataset, we can create a simple scatter plot before and after scaling the features. We’ll use the well-known Iris dataset for this demonstration.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# Load the Iris dataset
data = load_iris()
X = data.data
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit and transform the data using StandardScaler
X_scaled = scaler.fit_transform(X)
# Plot original and scaled features
plt.figure(figsize=(10, 5))
# Original features (first two columns)
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=data.target)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Original Features')
# Scaled features (first two columns)
plt.subplot(1, 2, 2)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=data.target)
plt.xlabel('Scaled Feature 1')
plt.ylabel('Scaled Feature 2')
plt.title('Scaled Features')
plt.tight_layout()
plt.show()
In this visualization, we compare the scatter plots of the first two features before and after applying StandardScaler. The color of the points represents different classes in the Iris dataset. You can see how scaling transforms the data to have zero mean and unit variance, while maintaining the same relative relationships between data points.
Important Concepts in Scikit-Learn Preprocessing StandardScaler
- Mean and Variance
- Z-Score
- Feature Scaling
- Normalization
- Standard Deviation
To Know Before You Learn Scikit-Learn Preprocessing StandardScaler?
- Basic understanding of machine learning concepts
- Familiarity with feature scaling and normalization
- Knowledge of mean, variance, and standard deviation
- Understanding of Z-score and its application
- Awareness of the impact of feature scaling on different algorithms
What’s Next?
After learning about Scikit-Learn Preprocessing StandardScaler, you can delve into the following topics:
- MinMaxScaler: Learn about another popular method for feature scaling.
- RobustScaler: Explore a robust alternative for handling outliers during scaling.
- Normalization: Understand the differences between normalization and standardization.
- Principal Component Analysis (PCA): Discover dimensionality reduction techniques.
- Machine Learning Algorithms: Explore how different algorithms are affected by scaling.
Relevant entities
| Entity | Properties |
|---|---|
| Scikit-Learn Preprocessing StandardScaler | Standardizes features Zero mean and unit variance Enhances algorithm convergence |
| Feature Scaling | Normalization of feature values Ensures consistent scales Improves algorithm performance |
| Feature Transformation | Modification of feature representations Enables better algorithm performance Includes scaling, encoding, etc. |
| Data Preprocessing | Initial data preparation Cleaning, transformation, and scaling Essential for accurate modeling |
| Machine Learning Algorithms | Models that learn patterns from data Include regression, classification, clustering, etc. Performance influenced by feature scaling |
| Outliers | Data points significantly different from others Affect mean and variance Considered during feature scaling |
sources
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html">Scikit-Learn Documentation – Preprocessing Data: StandardScaler
- standardscaler-and-minmaxscaler-transforms-in-python/">Machine Learning Mastery – How to Use StandardScaler and MinMaxScaler Transformations in Python
- Analytics Vidhya – A Comprehensive Guide to Normalization Techniques in Python
- standardscaler-fit-method-work-in-scaling-data">Stack Overflow – How to Use StandardScaler in Scikit-Learn
Conclusion
Scikit-Learn’s StandardScaler is a powerful tool for standardizing features and improving the performance of various machine learning algorithms. By bringing features to a common scale, you ensure fair treatment for each feature, leading to better model results.