
The accuracy machine learning is a metric that measures how well a model can predict outcomes on new data.
In this article, we’ll explore what accuracy means in the context of machine learning, why it’s important, and how you can improve it.
What is Accuracy?
Accuracy is the measure of how well a machine learning model can predict outcomes on new data. It’s calculated by dividing the number of correct predictions by the total number of predictions made. The result is a percentage that represents the model’s accuracy.
Why is Accuracy Important?
Accuracy is important because it determines how useful a machine learning model is in practice. If a model has low accuracy, it won’t be able to make accurate predictions on new data, rendering it useless. On the other hand, a model with high accuracy can be used to make predictions with confidence, leading to better decision-making and improved outcomes.
How to Calculate Accuracy?
To calculate accuracy, you first need to split your dataset into training and testing data. Then you train your model on the training data and evaluate its performance on the testing data. You can calculate accuracy by comparing the predicted values to the actual values and counting the number of correct predictions.
How to Evaluate the Accuracy in Python
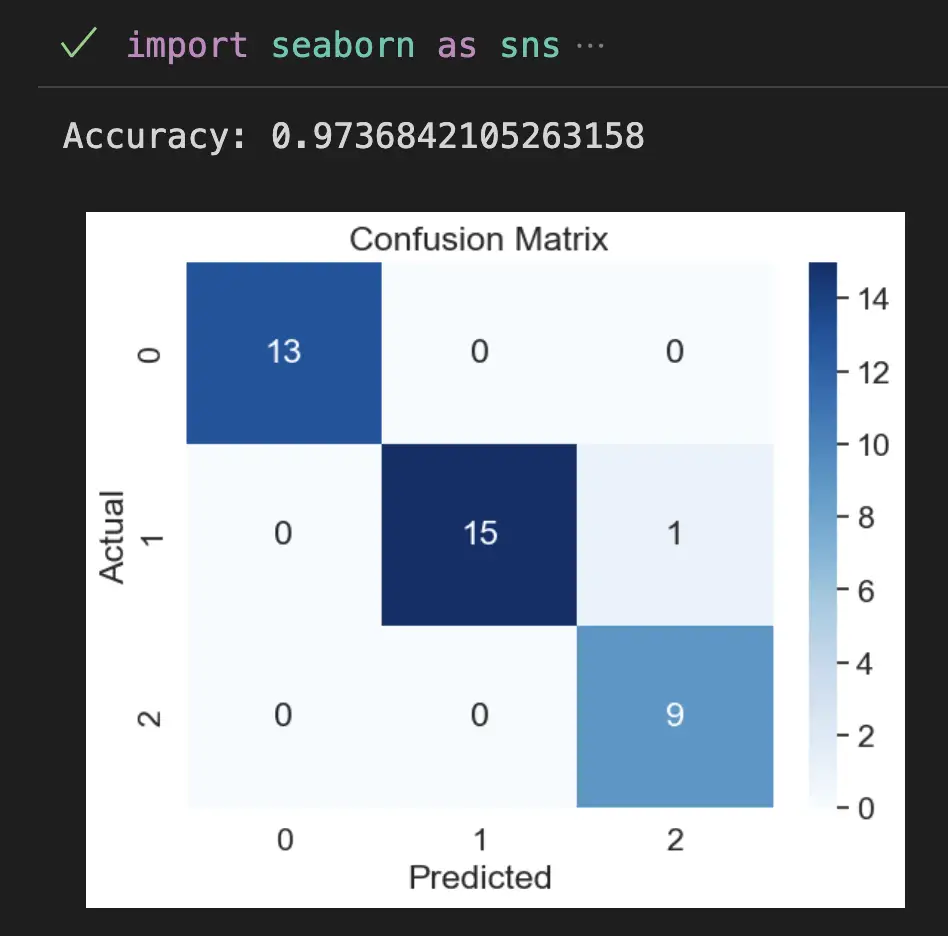
To evaluate the accuracy of a machine learning model in Python, use the score() method on the trained machine learning model. In this case with will apply the score() method to the fitted knn classifier object.
Then, we’ll plot a heatmap showing off the confusion matrix.
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# Load the Iris dataset
iris = load_iris()
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
# Train a KNN classifier with k=5
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = knn.predict(X_test)
# Calculate the accuracy of the model
accuracy = knn.score(X_test, y_test)
print('Accuracy:', accuracy)
# Create a confusion matrix using Seaborn
sns.set(font_scale=1.4)
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
How to Improve the Accuracy of Machine Learning Models
To improve the accuracy of machine learning models, perform a number of the following tasks:
- Feature Selection
- Feature Engineering
- Model Selection
- Hyperparameter Tuning
- Cross-Validation
Feature Selection
Selecting the right features is critical for improving accuracy. You should choose features that are relevant to the problem you’re trying to solve.
Feature Engineering
Feature engineering is the process of transforming raw data into features that are more meaningful to a machine learning model. This can include things like scaling, normalization, and one-hot encoding.
Model Selection
Choosing the right model is important for improving accuracy. Different models work better for different types of problems, so it’s important to choose the one that’s best suited for your problem.
Hyperparameter Tuning
Hyperparameters are the parameters that are set before training a model. Tuning these parameters can significantly improve accuracy.
Cross-Validation
Cross-validation is a technique used to evaluate the performance of a model. It involves splitting the dataset into multiple parts and training and testing the model on each part.
This code loads the Iris dataset, splits it into training and testing sets, trains a KNN classifier with k=5, predicts the labels of the test set, calculates the accuracy of the model, creates a confusion matrix using Seaborn, and finally visualizes the accuracy of the model using a barplot.
Important Concepts in Accuracy
- Confusion matrix
- Precision, recall, F1 score
- ROC curve
- Bias-variance tradeoff
- Cross-validation
- Overfitting and underfitting
- Ensemble methods
To Know Before You Learn Accuracy
- Basics of machine learning
- Supervised learning
- Classification and regression
- Model evaluation metrics
- Data preprocessing techniques
- Model selection techniques
- Basic programming skills in Python
What’s Next?
- Precision, recall, F1 score
- ROC curve
- Confusion matrix
- Bias-variance tradeoff
- Cross-validation techniques
- Model selection techniques
- Hyperparameter tuning
- Ensemble methods
Useful Python Libraries for Accuracy
- scikit-learn: accuracy_score, confusion_matrix
- numpy: mean
- pandas: read_csv
- matplotlib: pyplot, figure
Datasets useful for Accuracy Testing
Iris
# Python example
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
MNIST
# Python example
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784')
X, y = mnist['data'], mnist['target']
Wine
# Python example
from sklearn.datasets import load_wine
wine = load_wine()
X, y = wine.data, wine.target
Relevant Entities
| Entity | Properties |
|---|---|
| Accuracy | The measure of how well a machine learning model can predict outcomes on new data |
| Training Data | The dataset used to train a machine learning model |
| Testing Data | The dataset used to evaluate a machine learning model’s performance |
| Feature Selection | The process of selecting the most relevant features for a machine learning model |
| Feature Engineering | The process of transforming raw data into features that are more meaningful to a machine learning model |
| Model Selection | The process of selecting the best machine learning model for a given problem |
| Hyperparameter Tuning | The process of optimizing the parameters of a machine learning model to improve its performance |
| Cross-Validation | A technique used to evaluate the performance of a machine learning model by splitting the dataset into multiple parts and training and testing the model on each part |
Conclusion
Accuracy is the ultimate metric for machine learning models. It measures how well a model can predict outcomes on new data. Improving accuracy is crucial for making accurate predictions and better decision-making. By following the tips mentioned above, you can improve the accuracy of your machine learning models and make better predictions.
sources
- Towards Data Science: “Accuracy, Precision, Recall or F1?” https://towardsdatascience.com/accuracy-precision-recall-or-f1-331fb37c5cb9
- Scikit-learn documentation: “Model selection: choosing estimators and their parameters” https://scikit-learn.org/stable/tutorial/statistical_inference/model_selection.html
- Machine Learning Mastery: “A Gentle Introduction to Bias-Variance Trade-Off in Machine Learning”
- Kaggle: “How to measure and solve bias and variance”
Stanford University CS229: “Machine Learning Cheat Sheet – Model Evaluation”
