
Natural Language Processing (NLP) is a field of study that focuses on the interaction between computers and human language. It involves teaching computers to understand, interpret, and generate human language in a way that is meaningful and useful to people. NLP is a subfield of Artificial Intelligence (AI) that has gained significant attention in recent years.
In this tutorial we will learn about natural language processing and show Python examples.
How NLP Works
NLP involves several steps to process and analyze human language. The first step is to break down the text into smaller units, such as words and phrases. This process is called tokenization. Once the text is tokenized, the next step is to assign meaning to each word. This process is called named entity recognition (NER).
Another important aspect of NLP is part-of-speech tagging, which involves identifying the grammatical function of each word in a sentence. This is useful for understanding the context and structure of a sentence. NLP also involves machine learning algorithms such as clustering and classification to analyze and categorize text data.
Applications of NLP
NLP has numerous applications in various industries. One of the most common applications is sentiment analysis, which involves analyzing customer reviews and social media posts to understand the sentiment towards a product or brand. NLP is also used in chatbots and virtual assistants to help users interact with machines in a more natural way.
Other applications of NLP include machine translation, speech recognition, and text summarization. NLP is also used in healthcare to analyze electronic medical records and assist with clinical decision-making. In the legal industry, NLP is used for e-discovery and contract analysis.
Steps to Learn Natural Language Processing
- Learn the basics of programming and data structures.
- Learn Python, which is the most popular language for NLP.
- Learn about text preprocessing techniques, such as tokenization, stemming, and stop word removal.
- Learn about text representation techniques, such as bag-of-words and TF-IDF.
- Learn about popular NLP libraries, such as NLTK, spaCy, and Gensim.
- Learn about machine learning algorithms for NLP, such as Naive Bayes, Support Vector Machines, and Random Forests.
- Learn about deep learning techniques for NLP, such as Recurrent Neural Networks (RNNs) and Transformers.
- Learn about common NLP tasks, such as sentiment analysis, named entity recognition, and machine translation.
- Work on hands-on projects to apply your knowledge and build practical skills.
- Stay up-to-date with the latest research and trends in NLP.
Important Concepts in Natural Language Processing (NLP)
- Tokenization
- Named Entity Recognition (NER)
- Part-of-speech (POS) tagging
- Stemming and Lemmatization
- Sentiment Analysis
- Text Classification
- Word Embeddings
- Language Modeling
- Machine Translation
- Question Answering
- Dialogue Systems
- Information Extraction
Getting Started
For this NLP tutorial, you will need to install Python along with the most popular natural language processing libraries used in this guide.
Open the Terminal and type (might take a while to run):
pip install nltk
pip install -U scikit-learn
pip install gensim
pip install networkx
pip install googletrans==4.0.0-rc1
pip install graphviz
pip3 install chatterbot
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download en_core_web_smWhat is Tokenization
Tokenization is the process of breaking down a large text into smaller chunks called tokens. These tokens are usually words, phrases, or sentences. Tokenization is a crucial step in many Natural Language Processing (NLP) tasks.
Here’s some sample Python code to illustrate tokenization using the popular NLTK library:
import nltk
nltk.download('punkt')
text = "Tokenization is the process of breaking down a large text into smaller chunks called tokens. These tokens are usually words, phrases, or sentences."
tokens = nltk.word_tokenize(text)
print(tokens)
You will see in the output a Python list with the sentence split into tokens.
['Tokenization', 'is', 'the', 'process', 'of', 'breaking', 'down', 'a', 'large', 'text', 'into', 'smaller', 'chunks', 'called', 'tokens', '.', 'These', 'tokens', 'are', 'usually', 'words', ',', 'phrases', ',', 'or', 'sentences', '.']Visualize tokenization.
import nltk
import matplotlib.pyplot as plt
nltk.download('punkt')
text = "Tokenization is the process of breaking down a large text into smaller chunks called tokens. These tokens are usually words, phrases, or sentences."
tokens = nltk.word_tokenize(text)
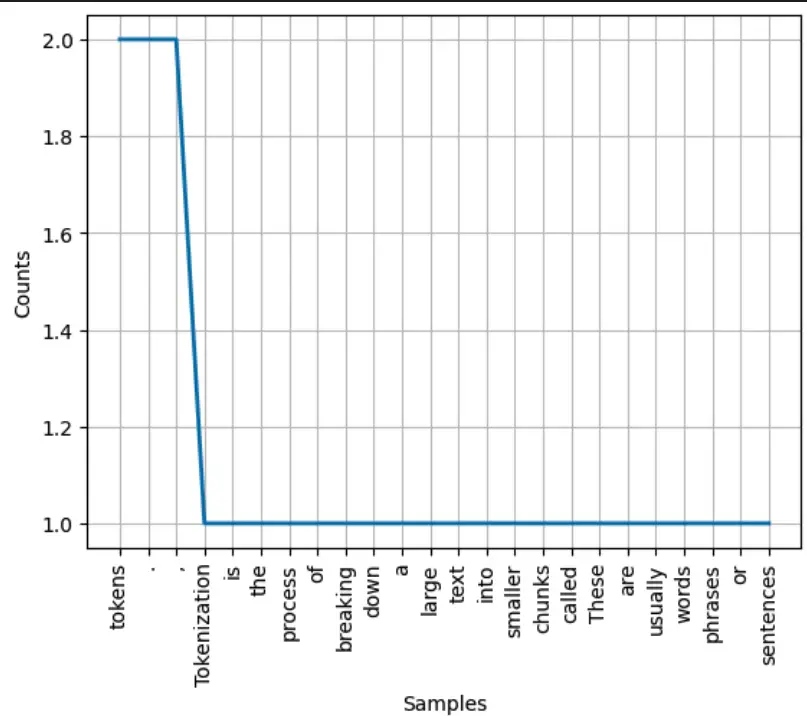
freq_dist = nltk.FreqDist(tokens)
freq_dist.plot(30)
This code creates a frequency distribution of the tokens and plots the 30 most common tokens in a histogram. This visualization can help us better understand the structure and content of the text.
For more example using NLTK, check out the tutorial on how to do natural language processing with NLTK.
What is Part-of-Speech Tagging
Part-of-speech (POS) tagging is the process of labeling each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, or adverb. This information is used in many natural language processing tasks, such as information retrieval, machine translation, and sentiment analysis.
Here’s some sample Python code to illustrate POS tagging using the popular NLTK library:
import nltk
nltk.download('averaged_perceptron_tagger')
text = "Tokenization is the process of breaking down a large text into smaller chunks called tokens."
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
print(pos_tags)
In the output, you will see a list of tokens, but this time, POS tags are added along with the token as a Python tuple. If you don’t know what these mean, make sure to read our blog post on nltk POS tags.
[('Tokenization', 'NN'), ('is', 'VBZ'), ('the', 'DT'), ('process', 'NN'), ('of', 'IN'), ('breaking', 'VBG'), ('down', 'RP'), ('a', 'DT'), ('large', 'JJ'), ('text', 'NN'), ('into', 'IN'), ('smaller', 'JJR'), ('chunks', 'NNS'), ('called', 'VBD'), ('tokens', 'NNS'), ('.', '.')]Visualize Part-of-Speech Tagging.
import nltk
import matplotlib.pyplot as plt
nltk.download('averaged_perceptron_tagger')
text = "Tokenization is the process of breaking down a large text into smaller chunks called tokens."
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
pos_freq = {}
for tag in pos_tags:
pos = tag[1]
if pos in pos_freq:
pos_freq[pos] += 1
else:
pos_freq[pos] = 1
labels = pos_freq.keys()
sizes = pos_freq.values()
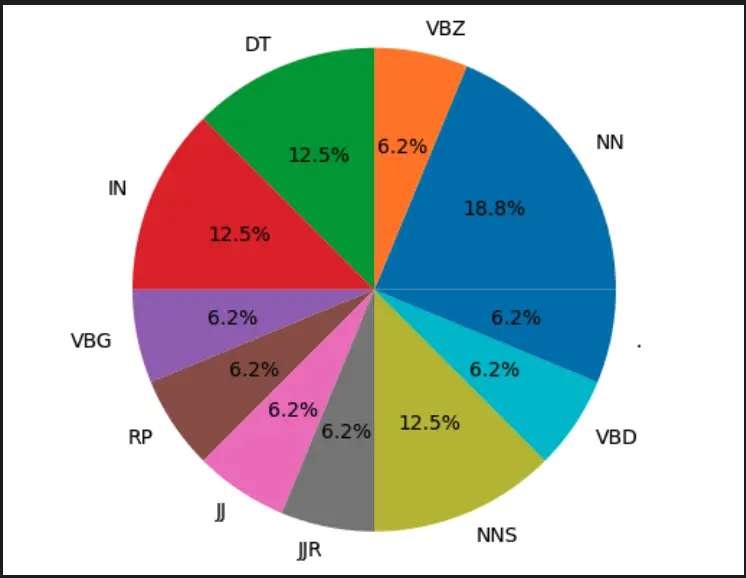
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.axis('equal')
plt.show()
This code creates a frequency distribution of the part-of-speech tags and plots them in a pie chart. This visualization can help us understand the distribution of the different parts of speech in the text.
What is Stemming
Stemming is the process of reducing inflected words to their base or root form, often resulting in the creation of words that may not be actual words. For example, “jumping”, “jumps”, “jumped” all become “jump” after stemming.
In Python, the NLTK library provides a stemmer module that can perform stemming. Here’s an example code to illustrate stemming using the Porter Stemmer:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["jumping", "jumps", "jumped"]
stemmed_words = [stemmer.stem(word) for word in words]
print(stemmed_words)
The code produces an output showing each word of the list into their stemmed version, which shows that they all have the same stem.
['jump', 'jump', 'jump']Visualize Stemming. This code will produce a bar chart showing the frequency of each stemmed word:
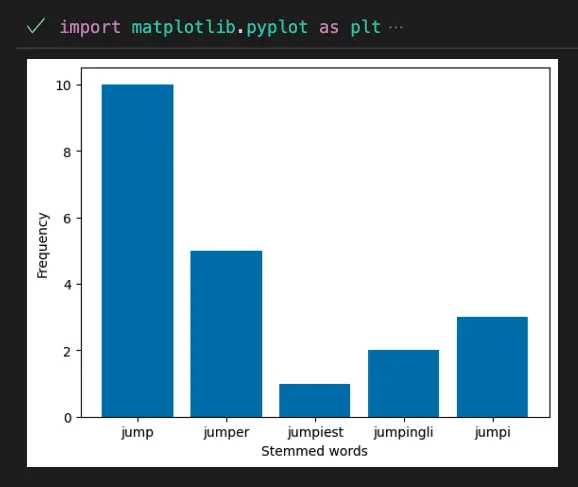
import matplotlib.pyplot as plt
word_freq = {"jumping": 5, "jumps": 3, "jumped": 2, "jumper": 1, "jumpers": 4, "jumpiest": 1, "jumpingly": 2, "jumpiness": 3}
stemmed_word_freq = {}
for word, freq in word_freq.items():
stemmed_word = stemmer.stem(word)
stemmed_word_freq[stemmed_word] = stemmed_word_freq.get(stemmed_word, 0) + freq
plt.bar(stemmed_word_freq.keys(), stemmed_word_freq.values())
plt.xlabel("Stemmed words")
plt.ylabel("Frequency")
plt.show()
The output shows the frequency of each stems.
What is Sentiment Analysis
Sentiment analysis is the process of identifying and extracting opinions or sentiments from a given text. It involves classifying the polarity of a text as positive, negative, or neutral. This technique has numerous applications, including marketing research, customer service, and social media analysis.
In Python, the NLTK library provides a sentiment analysis module that uses the VADER (Valence Aware Dictionary and sEntiment Reasoner) lexicon to perform sentiment analysis. Here’s an example code to illustrate sentiment analysis using the VADER module:
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
text = "I love this product! It's the best one I've ever used."
analyzer = SentimentIntensityAnalyzer()
scores = analyzer.polarity_scores(text)
print(scores)
The polarity_scores() method returns a dictionary containing the scores for negative, neutral, positive, and compound sentiment. The compound score is a metric that ranges from -1 (most negative) to 1 (most positive).
{'neg': 0.0, 'neu': 0.479, 'pos': 0.521, 'compound': 0.8655}To visualize the sentiment scores, we can use a pie chart using Matplotlib:
import matplotlib.pyplot as plt
labels = ['Negative', 'Neutral', 'Positive']
sizes = [scores['neg'], scores['neu'], scores['pos']]
colors = ['red', 'yellow', 'green']
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%')
plt.axis('equal')
plt.show()

What is Text Classification
Text classification is a common NLP task where a given text document is classified into predefined categories. For instance, spam detection is an example of text classification, where the task is to classify an email as either spam or not spam.
Here is a short Python code to illustrate text classification:
# Import the necessary libraries
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix
# Load the dataset
newsgroups = fetch_20newsgroups(subset='all')
X = newsgroups.data
y = newsgroups.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Vectorize the text data
vectorizer = TfidfVectorizer()
X_train_vect = vectorizer.fit_transform(X_train)
X_test_vect = vectorizer.transform(X_test)
# Train the model
model = MultinomialNB()
model.fit(X_train_vect, y_train)
# Predict on the test set
y_pred = model.predict(X_test_vect)
# Evaluate the performance
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Confusion matrix:', confusion_matrix(y_test, y_pred))
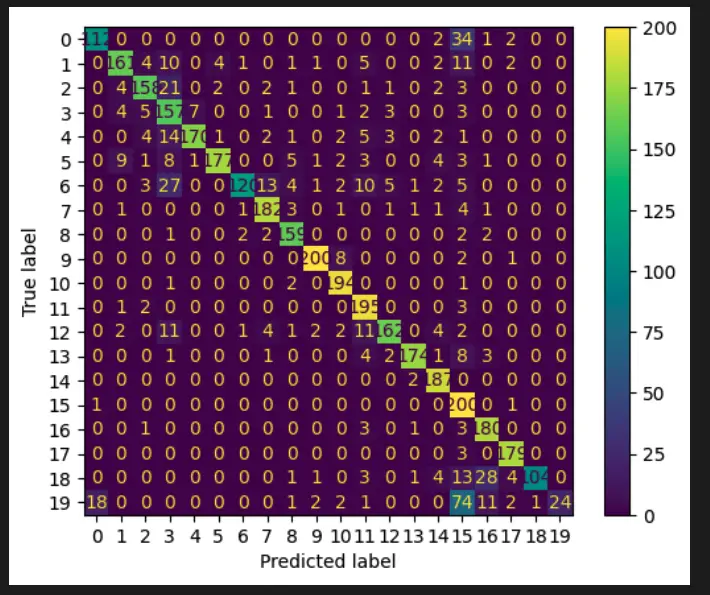
The above code loads a spam dataset, preprocesses the text data, vectorizes the text data using TfidfVectorizer, trains a Naive Bayes classifier on the training set, and predicts on the test set. Finally, it evaluates the performance using accuracy and confusion matrix.
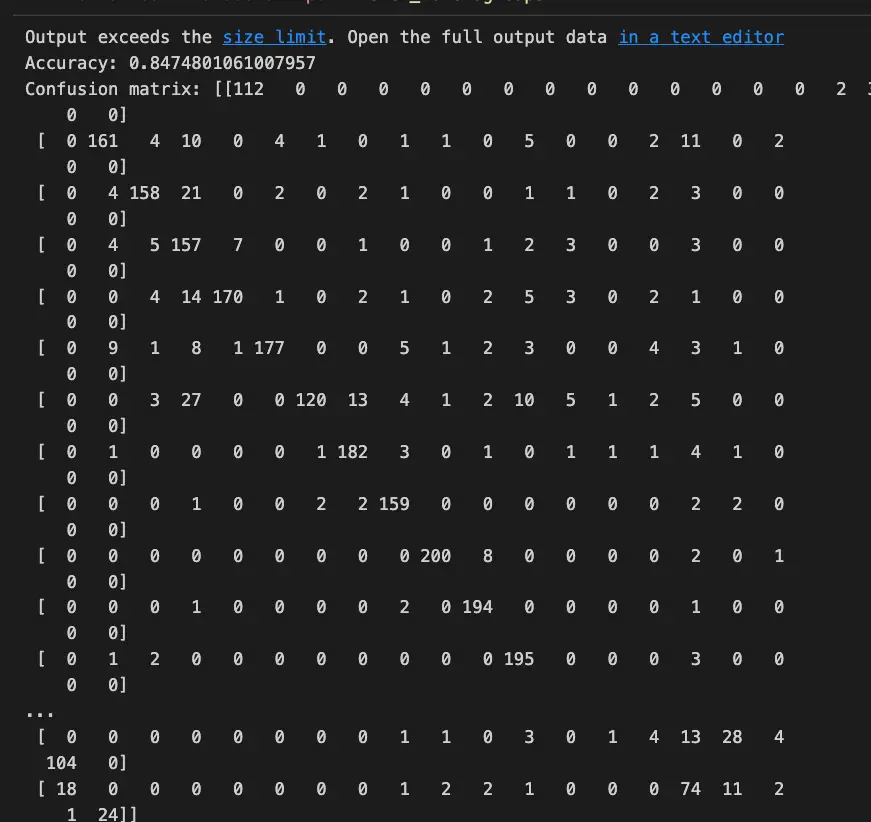
This output is not so beautiful, we can improve it using the plot_confusion_matrix method.
# Import the necessary libraries
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix, plot_confusion_matrix
# Load the dataset
newsgroups = fetch_20newsgroups(subset='all')
X = newsgroups.data
y = newsgroups.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Vectorize the text data
vectorizer = TfidfVectorizer()
X_train_vect = vectorizer.fit_transform(X_train)
X_test_vect = vectorizer.transform(X_test)
# Train the model
model = MultinomialNB()
model.fit(X_train_vect, y_train)
# Predict on the test set
y_pred = model.predict(X_test_vect)
# Evaluate the performance
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Confusion matrix:')
plot_confusion_matrix(model, X_test_vect, y_test)
plt.show()
For more example using Scikit-learn, check out the tutorial on how to do natural language processing with Scikit-learn.
What are Word embeddings?
Word embeddings are a type of representation of words in a high-dimensional space, where words with similar meanings are close to each other. They are widely used in natural language processing tasks, such as sentiment analysis, text classification, and machine translation. Word embeddings capture the meaning of a word based on its context in a sentence.
Here’s an example of how to generate word embeddings using the Gensim library in Python:
from gensim.models import Word2Vec
sentences = [["the", "cat", "sat", "on", "the", "mat"],
["the", "dog", "ran", "in", "the", "park"],
["the", "bird", "sang", "in", "the", "tree"]]
model = Word2Vec(sentences, vector_size=10, window=3, min_count=1, workers=4)
# Get the vector representation of a word
vector = model.wv['cat']
print(vector)
This code generates word embeddings using the Word2Vec algorithm on a small corpus of three sentences. The resulting vectors have a dimensionality of 10. We can obtain the vector representation of a word by using the wv attribute of the trained Word2Vec model.
[-0.00410223 -0.08368949 -0.05600012 0.07104538 0.0335254 0.0722567
0.06800248 0.07530741 -0.03789154 -0.00561806]Let’s make it clearer with a visualization:
Here’s an example of how to visualize word embeddings using the t-SNE algorithm in Python:
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
sentences = [["the", "cat", "sat", "on", "the", "mat"],
["the", "dog", "ran", "in", "the", "park"],
["the", "bird", "sang", "in", "the", "tree"]]
model = Word2Vec(sentences, vector_size=10, window=3, min_count=1, workers=4)
# Get the vector representation of a word
words = model.wv.index_to_key
vectors = model.wv[words]
# Reduce the dimensionality of the word vectors using PCA
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
# Plot the 2D embeddings
plt.scatter(vectors_2d[:, 0], vectors_2d[:, 1])
for i, word in enumerate(words):
plt.annotate(word, xy=(vectors_2d[i, 0], vectors_2d[i, 1]))
plt.show()
What is Language Modeling
Language modeling is the task of predicting the probability of the next word in a sequence given the previous words. It involves building a statistical model of language, which can be used to generate text or make predictions about text. Language modeling is a key component of many natural language processing tasks, such as speech recognition, machine translation, and text generation.
Here is a short Python code to train a simple language model using the Natural Language Toolkit (NLTK) library:
import nltk
from nltk.corpus import gutenberg
nltk.download('gutenberg')
# Load the text corpus
corpus = gutenberg.words('austen-emma.txt')
# Create a list of sentences
sentences = nltk.sent_tokenize(' '.join(corpus))
# Preprocess the sentences
preprocessed = []
for sentence in sentences:
tokens = nltk.word_tokenize(sentence.lower())
preprocessed.append(tokens)
# Train a bigram language model
model = nltk.BigramAssocMeasures()
finder = nltk.BigramCollocationFinder.from_documents(preprocessed)
finder.apply_freq_filter(5)
bigrams = finder.nbest(model.pmi, 20)
# Print the most frequent bigrams
print(bigrams)
This code loads a text corpus from the NLTK library, preprocesses it by tokenizing and lowercasing the sentences, and trains a bigram language model using the Pointwise Mutual Information (PMI) measure. The most frequent bigrams are then printed.
[('brunswick', 'square'), ('sore', 'throat'), ('mill', 'farm'), ('william', 'larkins'), ('baked', 'apples'), ('box', 'hill'), ('sixteen', 'miles'), ('maple', 'grove'), ('hair', 'cut'), ('south', 'end'), ('colonel', 'campbell'), ('protest', 'against'), ('robert', 'martin'), ('vast', 'deal'), ('five', 'couple'), ('ready', 'wit'), ('musical', 'society'), ('infinitely', 'superior'), ('donwell', 'abbey'), ('married', 'women')]To visualize the language model, we can create a network graph of the bigrams using the NetworkX library:
import networkx as nx
import matplotlib.pyplot as plt
# Create a network graph of the bigrams
graph = nx.Graph()
for bigram in bigrams:
graph.add_edge(bigram[0], bigram[1])
# Draw the network graph
pos = nx.spring_layout(graph)
nx.draw_networkx_nodes(graph, pos, node_size=200, node_color='lightblue')
nx.draw_networkx_edges(graph, pos, width=1, alpha=0.5, edge_color='gray')
nx.draw_networkx_labels(graph, pos, font_size=10, font_family='sans-serif')
plt.axis('off')
plt.show()

What is Machine Translation
Machine translation is a subfield of natural language processing that focuses on translating text from one language to another automatically using machine learning algorithms. It involves processing input text, generating a representation of its meaning, and then using that representation to generate the corresponding text in another language.
To illustrate machine translation in Python, we can use the Googletrans library which provides a simple interface to Google Translate API. Here is an example code that uses Googletrans to translate a sentence from English to French:
from googletrans import Translator
# Create a Translator object
translator = Translator(service_urls=['translate.google.com'])
# Define the text to be translated
text = "Hello, how are you today?"
# Translate the text to French
translation = translator.translate(text, dest='fr')
# Print the translation
print(translation.text)
Translated output:
Bonjour comment vas tu aujourd'hui?What is Question Answering in NLP?
Question answering (QA) is an NLP task where the goal is to find an answer to a question asked in natural language. This task involves both language understanding and information retrieval techniques.
To illustrate question answering in Python, we can use the Natural Language Toolkit (NLTK) library. Here’s an example:
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# Define the passage to search for answers
passage = "The quick brown fox jumps over the lazy dog. The dog, who was not very impressed by the fox, barked loudly and chased it away."
# Tokenize the passage into sentences
sentences = sent_tokenize(passage)
# Define the question to answer
question = "What did the dog do to the fox?"
# Tokenize the question
question_tokens = word_tokenize(question)
# Remove stopwords from the question
stopwords = set(stopwords.words('english'))
question_tokens = [word for word in question_tokens if word.lower() not in stopwords and word.isalpha()]
# Lemmatize the question tokens
lemmatizer = WordNetLemmatizer()
question_tokens = [lemmatizer.lemmatize(token) for token in question_tokens]
question_tokens = [x for x in question_tokens if '?' not in x]
# Find the sentence that contains the answer
answer = None
for sentence in sentences:
sentence_tokens = word_tokenize(sentence)
sentence_tokens = [word for word in sentence_tokens if word.lower() not in stopwords]
sentence_tokens = [lemmatizer.lemmatize(token) for token in sentence_tokens]
if set(question_tokens).issubset(set(sentence_tokens)):
answer = sentence
break
# Print the answer or a message if the answer cannot be found
if answer:
print(answer)
else:
print("Sorry, I couldn't find the answer to that question in the given passage.")
The output shows the answer:
The quick brown fox jumps over the lazy dog.This code takes a passage of text and a question and attempts to find an answer to the question within the passage. It tokenizes the passage into sentences and tokenizes the question, removes stopwords, and lemmatizes the tokens. It then searches each sentence for a match to the question tokens and prints the sentence that contains the answer.
What are Dialog Systems in NLP?
Dialog systems, also known as conversational agents or chatbots, are computer systems designed to engage in a natural language conversation with humans. They use natural language processing (NLP) and machine learning techniques to understand the user’s intent and generate appropriate responses. Dialog systems can be task-oriented, where they aim to accomplish specific tasks such as booking a flight, or they can be open-domain, where they aim to engage in open-ended conversations on a variety of topics.
To illustrate dialog systems, we can use the Python library ChatterBot. The following code demonstrates how to create a simple dialog system that responds to user input:
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
# Create a chatbot
chatbot = ChatBot('My Chatbot')
# Train the chatbot on the English corpus
trainer = ChatterBotCorpusTrainer(chatbot)
trainer.train('chatterbot.corpus.english')
# Get a response from the chatbot
response = chatbot.get_response('Hello, how are you?')
# Print the chatbot's response
print(response)
What is Information Extraction
Information extraction (IE) is the process of automatically extracting structured information from unstructured or semi-structured data sources. IE typically involves identifying named entities (e.g., people, places, organizations) and relationships between them from text data.
In Python, one popular library for information extraction is spaCy. Below is an example of using spaCy to extract named entities from a sample text:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "John Smith is a software engineer at Google in New York."
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
John Smith PERSON
Google ORG
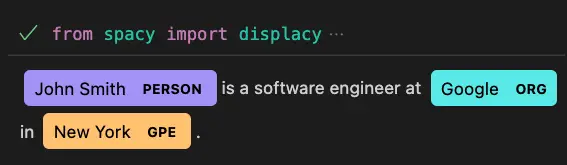
New York GPEVisualize the output.
from spacy import displacy
displacy.render(doc, style="ent", jupyter=True)
For more example using SpaCy, check out the tutorial on how to do natural language processing with SpaCy.
The Importance of NLP in Today’s World
The rise of the digital age has resulted in an explosion of data. Much of this data is unstructured text data, such as emails, social media posts, and customer reviews. NLP helps make sense of this data by allowing machines to understand the meaning behind the text. This has numerous applications, from sentiment analysis to chatbots and virtual assistants.
The Future of NLP
NLP is a rapidly evolving field, and there is still much to be discovered and improved upon. As machine learning algorithms become more advanced, NLP is expected to become more accurate and efficient. NLP is also expected to play an increasingly important role in fields such as education, marketing, and customer service.
The development of more sophisticated chatbots and virtual assistants is also expected to drive the growth of NLP. As machines become more adept at understanding human language, they will be able to provide more personalized and meaningful interactions with users.
Conclusion
NLP is a field with enormous potential, and it is already making a significant impact on various industries. By enabling machines to understand and interpret human language, NLP is helping us make sense of the vast amounts of unstructured text data that we generate every day. As NLP continues to evolve, it is likely to play an even more significant role in our lives.
NLP Project Examples in Python
Example 1: Tokenization, POS tagging, and Sentiment Analysis
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
from nltk.sentiment import SentimentIntensityAnalyzer
text = "I am really excited about this new natural language processing project!"
tokens = word_tokenize(text)
pos_tags = pos_tag(tokens)
sentiment = SentimentIntensityAnalyzer().polarity_scores(text)
print("Tokens:", tokens)
print("POS tags:", pos_tags)
print("Sentiment:", sentiment)
Output:
Tokens: ['I', 'am', 'really', 'excited', 'about', 'this', 'new', 'natural', 'language', 'processing', 'project', '!']
POS tags: [('I', 'PRP'), ('am', 'VBP'), ('really', 'RB'), ('excited', 'VBN'), ('about', 'IN'), ('this', 'DT'), ('new', 'JJ'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('project', 'NN'), ('!', '.')]
Sentiment: {'neg': 0.0, 'neu': 0.593, 'pos': 0.407, 'compound': 0.6689}Example 2: Named Entity Recognition and Text Classification
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag, ne_chunk
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
text = "Steve Jobs was the CEO of Apple. Apple is located in California."
tokens = word_tokenize(text)
pos_tags = pos_tag(tokens)
named_entities = ne_chunk(pos_tags)
corpus = ["Steve Jobs was the CEO of Apple.", "Microsoft is located in Washington."]
labels = ["Apple", "Microsoft"]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
clf = MultinomialNB().fit(X, labels)
classification = clf.predict(vectorizer.transform([text]))
print("Named entities:", named_entities)
print("Classification:", classification)
Output:
Named entities: (S
(PERSON Steve/NNP)
(PERSON Jobs/NNP)
was/VBD
the/DT
(ORGANIZATION CEO/NNP)
of/IN
(GPE Apple/NNP)
./.
(PERSON Apple/NNP)
is/VBZ
located/VBN
in/IN
(GPE California/NNP)
./.)
Classification: ['Apple']Useful Python Libraries for Natural language processing (NLP)
- NLP with nltk: word_tokenize, pos_tag, ne_chunk, sent_tokenize, wordnet, NaiveBayesClassifier, DecisionTreeClassifier
- NLP with spacy: load, tokenizer, tagger, parser, ner, displacy
- NLP with gensim: corpora.Dictionary, models.Word2Vec, models.LdaModel
- NLP with textblob: TextBlob, Word, Blobber, Sentiment, TextBlobDE, TextBlobFR
- NLP with scikit-learn: CountVectorizer, TfidfVectorizer, SVC, KNeighborsClassifier, RandomForestClassifier
Useful Datasets to Practice Natural Language Processing
1. IMDb Movie Reviews Dataset
This dataset contains 50,000 movie reviews from IMDb labeled as positive or negative. The dataset can be downloaded from http://ai.stanford.edu/~amaas/data/sentiment/
# Python example to load IMDb movie reviews dataset
import nltk
nltk.download('movie_reviews')
from nltk.corpus import movie_reviews
2. 20 Newsgroups Dataset
This dataset contains around 20,000 newsgroup documents across 20 different newsgroups. The dataset can be downloaded from http://qwone.com/~jason/20Newsgroups/
# Python example to load 20 Newsgroups dataset
from sklearn.datasets import fetch_20newsgroups
categories = ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
twenty_train = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=42)
3. Reuters-21578 Dataset
This dataset contains news articles classified into 135 different topics. The dataset can be downloaded from https://archive.ics.uci.edu/ml/datasets/Reuters-21578+Text+Categorization+Collection
# Python example to load Reuters-21578 dataset
import nltk
nltk.download('reuters')
from nltk.corpus import reuters
To Know Before You Learn Natural language processing (NLP)?
- Python programming language
- Familiarity with machine learning concepts such as supervised and unsupervised learning
- Understanding of basic probability and statistics
- Knowledge of linear algebra
- Understanding of data preprocessing techniques such as data cleaning, normalization, and feature scaling
- Knowledge of text data preprocessing techniques such as tokenization, stemming, and lemmatization
- Understanding of different types of natural language processing tasks such as text classification, sentiment analysis, and named entity recognition
- Familiarity with popular NLP libraries such as NLTK, spaCy, and scikit-learn
What’s Next?
- Speech recognition and synthesis
- Text-to-speech synthesis
- Information retrieval and search engines
- Dialogue systems and chatbots
- Sentiment analysis and opinion mining
- Machine translation
- Named entity recognition
- Question-answering systems
- Text summarization and generation
- Advanced deep learning techniques for NLP, such as transformers and BERT.
Relevant Entities
| Entity | Properties |
|---|---|
| Corpus | A collection of text documents used for training and testing NLP models. |
| Word | The basic unit of language used to express a concept or idea. |
| Document | A text file or collection of text files that are analyzed and processed by NLP models. |
| Language Model | A statistical model used to predict the probability of a given sequence of words in a language. |
| Part-of-speech Tag | A label assigned to a word in a sentence indicating its grammatical category. |
| Named Entity | A specific type of noun phrase that refers to a specific entity, such as a person, organization, or location. |
| Sentiment | The emotional tone or attitude expressed in a piece of text, typically positive, negative, or neutral. |
| Tokenization | The process of breaking down a text into smaller units, such as words and phrases. |
Frequently Asked Questions
Analyzing, understanding, and generating human language.
Sentiment analysis, chatbots, machine translation, speech recognition, etc.
Ambiguity, context, idioms, slang, etc.
Tokenization, POS tagging, parsing, information extraction, etc.
Neural network-based models for text classification, machine translation, etc.
NLTK, spaCy, Gensim, Transformers, etc.
Sources:
Here are some popular pages for Natural language processing (NLP) in machine learning:
- Natural Language Toolkit (NLTK) official website: https://www.nltk.org/
- spaCy official website: https://spacy.io/
- Stanford NLP Group official website: https://nlp.stanford.edu/
