
In the world of machine learning, feature scaling is a crucial step that helps to improve the accuracy and efficiency of a model.
It involves scaling and normalizing the features or variables of a dataset to ensure that they are on a similar scale.
In this blog post, we will explore the importance of feature scaling, the techniques used, and its impact on machine learning models.
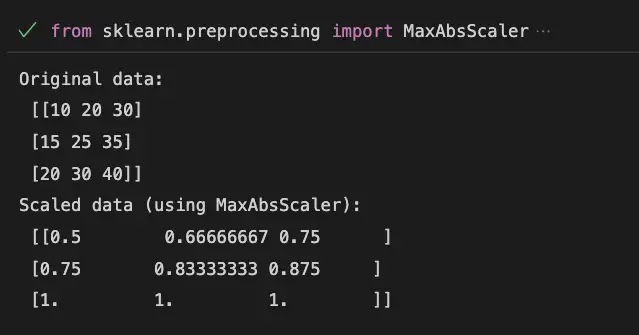
Below is an example of what we will achieve with feature scaling.
Why is feature scaling important?
In machine learning, algorithms such as K-Nearest Neighbors, Support Vector Machines, and Neural Networks are heavily influenced by the scale of the input features.
If the features are not on the same scale, some features may dominate the others, causing biased results. Therefore, feature scaling helps to bring all features on the same scale and avoid this bias. Additionally, scaling also helps to speed up the learning process, allowing for faster convergence and better accuracy.
Techniques for feature scaling
There are several techniques for feature scaling, but the two most commonly used techniques are:
Standardization
Standardization is a scaling technique that transforms the data to have a mean of 0 and a standard deviation of 1. This technique is applied when the data is normally distributed or when the data distribution is unknown. The formula for standardization is:
x' = (x - mean(x)) / std(x)
where x is the original feature, mean(x) is the mean of the feature, std(x) is the standard deviation of the feature, and x’ is the standardized feature.
Min-Max scaling
Min-max scaling is a scaling technique that scales the data to a fixed range, typically between 0 and 1. This technique is used when the data is not normally distributed. The formula for min-max scaling is:
x' = (x - min(x)) / (max(x) - min(x))
where x is the original feature, min(x) is the minimum value of the feature, max(x) is the maximum value of the feature, and x’ is the scaled feature.
Impact on machine learning models
Feature scaling can have a significant impact on the performance of machine learning models.
Without feature scaling, the performance of some algorithms can be severely affected. For example, in K-Nearest Neighbors, the distance between the points is calculated using Euclidean distance.
If the features are not scaled, the algorithm may give more weight to features with larger scales.
Therefore, the result may be biased towards the larger scale features. Similarly, in Support Vector Machines, the regularization parameter is sensitive to the scale of the features. If the features are not scaled, the regularization parameter may not be optimized correctly, leading to a suboptimal solution.
Python code Examples
Standardization example with Scikit-Learn (StandardScaler)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)Check out standardscaler">Stackoverflow for more examples.
Min-Max scaling example with Scikit-Learn (MinMaxScaler)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_features = scaler.fit_transform(features)Check out normalize-columns-of-pandas-data-frame">Stackoverflow for more examples.
MaxAbsScaler with Scikit-Learn
from sklearn.preprocessing import MaxAbsScaler
import numpy as np
# create sample data
data = np.array([[10, 20, 30], [15, 25, 35], [20, 30, 40]])
# create MaxAbsScaler object
scaler = MaxAbsScaler()
# fit and transform the data
scaled_data = scaler.fit_transform(data)
print("Original data:\n", data)
print("Scaled data (using MaxAbsScaler):\n", scaled_data)
In this example, we first import the MaxAbsScaler class from the sklearn.preprocessing module and numpy. We then create a sample dataset data, which is a 3×3 matrix of numerical values.
Next, we create a MaxAbsScaler object scaler.
Then, we fit and transform the data using the fit_transform() method of the scaler object. This scales the data so that the absolute maximum value of each feature is 1.
Scaling with SciPy
import numpy as np
from scipy import stats
from scipy.stats.mstats import winsorize
# create sample data
data = np.array([[10, 20, 30], [15, 25, 35], [20, 30, 40]])
# perform standardization with scale
scaled_data = stats.zscore(data)
# perform robust scaling with robust_scale
robust_scaled_data = winsorize(data, limits=[0.1, 0.1])
# perform min-max scaling with minmax_scale
minmax_scaled_data = (data - data.min(axis=0)) / (data.max(axis=0) - data.min(axis=0))
print("Original data:\n", data)
print("Scaled data (using stats.zscore):\n", scaled_data)
print("Robust scaled data (using stats.mstats.robust_scale):\n", robust_scaled_data)
print("Min-max scaled data (using stats.minmax_scale):\n", minmax_scaled_data)In this example, we first import the necessary libraries numpy and scipy.stats, which contains the zscore, robust_scale, and minmax_scale functions. We then create a sample dataset data, which is a 3×3 matrix of numerical values.
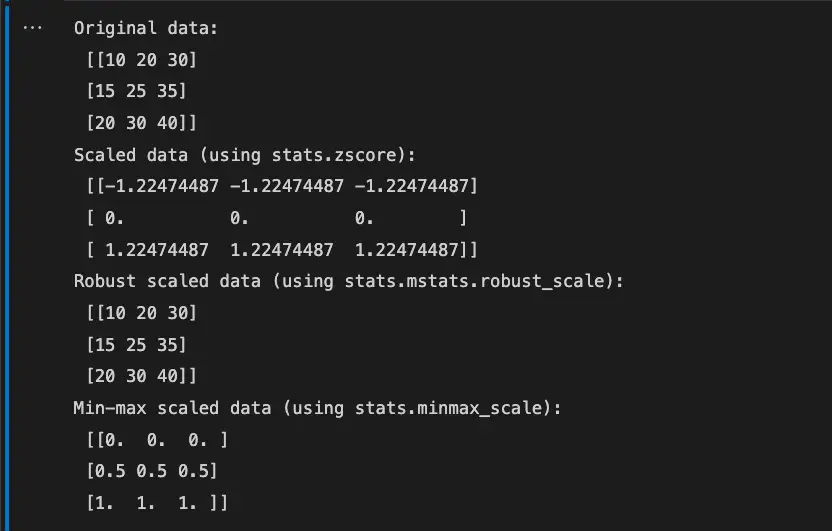
Next, we perform feature scaling using each of the three functions.
The zscore function performs standardization, which means it scales the data to have a mean of 0 and a standard deviation of 1.
The robust_scale function performs robust scaling, which means it scales the data using robust estimators that are less sensitive to outliers than the standard mean and standard deviation.
The minmax_scale function performs min-max scaling, which means it scales the data to a specified range (usually between 0 and 1).
Finally, we print the original data and the scaled data for each function to the console.
Useful Python Libraries for Feature scaling
- Scikit-learn: StandardScaler, MinMaxScaler, MaxAbsScaler
- SciPy: scale, robust_scale, minmax_scale
- NumPy: divide, subtract, multiply, add
Datasets useful for Feature scaling
Wine Quality Dataset
from sklearn.datasets import load_wine
wine_data = load_wine()
X = wine_data.data
y = wine_data.target
Boston Housing Dataset
from sklearn.datasets import load_boston
boston_data = load_boston()
X = boston_data.data
y = boston_data.target
Important Concepts in Feature scaling
- Normalization
- Standardization
- Min-max scaling
- Z-score
- Effect of scaling on machine learning models
Relevant entities
| Entities | Properties |
|---|---|
| Features | Numerical values that represent characteristics of an object or phenomenon |
| K-Nearest Neighbors algorithm | An algorithm that classifies data points based on the class of their neighboring points |
| Support Vector Machines | A supervised learning algorithm used for classification and regression analysis |
| Neural Networks | A type of machine learning algorithm inspired by the structure of the human brain |
| Standardization | A feature scaling technique that transforms the data to have a mean of 0 and a standard deviation of 1 |
| Min-Max scaling | A feature scaling technique that scales the data to a fixed range, typically between 0 and 1 |
Frequently asked questions
Scaling and normalizing the features or variables of a dataset to ensure that they are on a similar scale.
It avoids bias and speeds up the learning process.
Standardization and Min-Max scaling.
K-Nearest Neighbors, Support Vector Machines, and Neural Networks.
Conclusion
In conclusion, feature scaling is a critical step in machine learning that helps to improve the accuracy and efficiency of models. By bringing all features on the same scale, feature scaling helps to avoid bias and speed up the learning process. Standardization and Min-Max scaling are the two most commonly used techniques for feature scaling. It is essential to keep in mind that the choice of scaling technique may vary depending on the data and the algorithm used.
