
The check_cv function is part of Scikit-learn’s model_selection module and is used for validating cross-validation strategies.
What is check_cv?
The “sklearn.model_selection.check_cv” function is a utility function provided by scikit-learn (sklearn). It is used for validating and generating cross-validation objects.
Cross-validation is a technique used in machine learning to assess the performance of a predictive model on an independent dataset. It involves partitioning the data into multiple sets or “folds” and performing training and testing on these folds iteratively.
The “check_cv” function helps in the creation of cross-validation objects. It takes a parameter called “cv” which can be an integer representing the number of folds, a cross-validation object, or a strategy string. It then returns a validated cross-validator object. The returned object can be used with other methods in sklearn that require a cross-validation strategy, such as model selection and evaluation.
In summary, “sklearn.model_selection.check_cv” is a useful function in scikit-learn that facilitates the creation and validation of cross-validation objects, enabling efficient evaluation of machine learning models.
check_cv Python Examples
Example 1: Using KFold as a CV splitter
from sklearn.model_selection import check_cv
from sklearn.model_selection import KFold
cv = check_cv(KFold(n_splits=5))
print(cv)
KFold(n_splits=5, random_state=None, shuffle=False)Example 2: Using custom CV splitter with check_cv
from sklearn.model_selection import check_cv
class CustomCV:
def __init__(self, num_splits):
self.num_splits = num_splits
def get_n_splits(self, X=None, y=None, groups=None):
return self.num_splits
def split(self, X, y=None, groups=None):
# Implement custom split logic here
pass
cv = check_cv(CustomCV(num_splits=3))
print(cv)
<__main__.CustomCV object at 0x13f975250>Check cv Visualization in Python
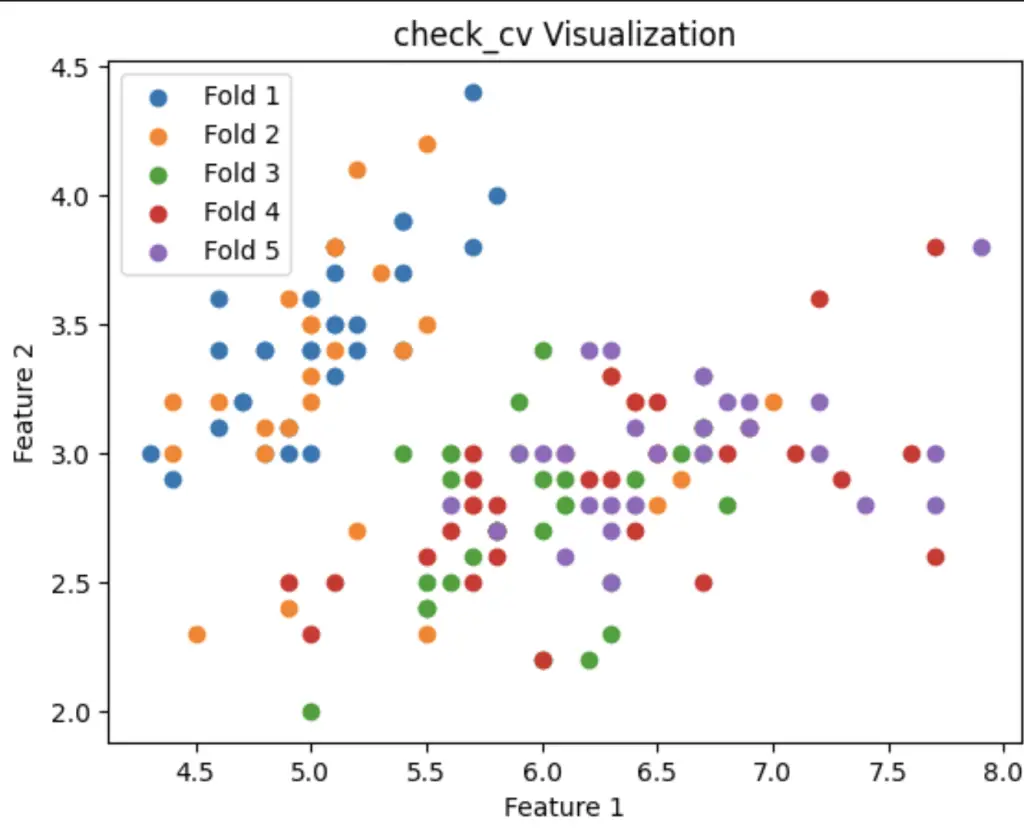
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import KFold, check_cv
# load iris dataset
iris = datasets.load_iris()
X, y = iris.data, iris.target
# define the number of folds
n_splits = 5
# create the cross-validation splits using KFold
kf = KFold(n_splits=n_splits)
cv = check_cv(cv=kf, y=y)
# visualize check_cv
fig, ax = plt.subplots()
for i, (_, test_index) in enumerate(cv.split(X, y)):
ax.scatter(X[test_index, 0], X[test_index, 1], label=f"Fold {i+1}")
ax.legend()
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("check_cv Visualization")
plt.show()
Useful Python Libraries for check_cv
- scikit-learn: sklearn.model_selection.check_cv, sklearn.model_selection.KFold, sklearn.model_selection.StratifiedKFold
- numpy: numpy.array
- pandas: pandas.DataFrame
Important Concepts in check_cv
- Cross-validation
- Training set
- Test set
- Stratified sampling
- K-fold cross-validation
- Random state
- Shuffle
- Train/test split
- Scikit-learn
- Machine learning
To Know Before You Learn check_cv?
- Understanding of machine learning principles and algorithms
- Familiarity with Python programming language
- Knowledge of basic statistics and probability theory
- Understanding of cross-validation techniques
- Familiarity with the scikit-learn library (sklearn) and its components
- Knowledge of data preprocessing and feature engineering techniques
- Understanding of model evaluation metrics and techniques
- Awareness of the importance of data splitting and validation in machine learning
- Familiarity with the concept of k-fold cross-validation
- Knowledge of the different types of model evaluation and validation strategies
What’s Next?
- Cross-validation techniques
- Hyperparameter tuning
- Evaluation metrics
- Feature selection
- Ensemble methods
- Deep learning algorithms
- Neural networks
- Natural language processing
- Recommendation systems
- Time series analysis
Conclusion
The sklearn.model_selection.check_cv function provides a convenient and flexible way to validate and cross-validate machine learning models. It allows for easy customization of the cross-validation strategy by accepting a CV splitter or an integer indicating the number of folds. Additionally, it supports stratified and shuffled splitting, making it suitable for a wide range of datasets and problems.
The function also offers built-in cross-validation iterators for common use cases, such as K-fold and stratified K-fold. Its integration with scikit-learn’s pipeline and grid search functionalities further enhances its usefulness. Overall, check_cv is a valuable tool for assessing the performance and generalizability of machine learning models.
