
Supervised learning is a fundamental concept in machine learning that involves training models to predict outcomes based on labeled data. In this article, we will explore the basics of supervised learning, its key components, and its practical implementation using Python.
We’ll cover both regression (predicting numerical values) and classification (categorizing data) tasks. You’ll understand how features and labels play crucial roles in model training. Through concise Python examples, we’ll demonstrate the use of popular libraries like scikit-learn and TensorFlow.
From linear regression to decision trees and neural networks, you’ll gain insights into various supervised learning algorithms. By the end, you’ll have a clear understanding of supervised learning’s significance and the ability to apply these concepts using Python.
What is Supervised Learning?
Supervised learning is a type of machine learning where the model learns from labeled training data.
- Input data is paired with corresponding target labels.
- The model generalizes patterns to make predictions on new, unseen data.
How Does Supervised Learning Work?
Data is split into training and testing sets to evaluate model performance.
- Features are extracted from the training data.
- The model learns by comparing its predictions with actual labels.
- Algorithms adjust their internal parameters to minimize prediction errors.
Why is Supervised Learning Important?
Supervised learning enables various practical applications.
- Classification: Assigning labels to data points, like spam or not spam.
- Regression: Predicting continuous values, such as stock prices.
- Natural Language Processing: Language translation, sentiment analysis, and more.
What Are the Types of Supervised Learning?
The two common types of supervised learning are the classification and regression. A Classification sorts data into categories or classes. A Regression predicts numerical values within a range.
- Regression Algorithms:
- Linear Regression
- Polynomial Regression
- Ridge Regression
- Lasso Regression
- Elastic Net Regression
- Support Vector Regression (SVR)
- Decision Tree Regression
- Random Forest Regression
- Gradient Boosting Regression
- XGBoost Regression
- LightGBM Regression
- CatBoost Regression
- Classification Algorithms:
- Logistic Regression
- K-Nearest Neighbors (KNN)
- Support Vector Machines (SVM)
- Decision Trees
- Random Forests
- Gradient Boosting
- XGBoost
- LightGBM
- CatBoost
- Naive Bayes
- Neural Networks
How to Evaluate Supervised Learning Models?
Several metrics measure model performance.
- Accuracy: Ratio of correct predictions to total predictions.
- Precision: Proportion of true positive predictions in positive predictions.
- Recall: Proportion of true positives captured by the model.
- F1 Score: Harmonic mean of precision and recall.
What Are the Challenges in Supervised Learning?
Data quality, overfitting, and bias are common challenges.
- Insufficient or noisy data can lead to inaccurate models.
- Overfitting occurs when a model memorizes training data and performs poorly on new data.
- Bias can emerge if the training data is unrepresentative of the real-world scenarios.
How to Improve Supervised Learning?
Feature engineering and regularization help enhance model performance.
- Feature engineering involves selecting and transforming relevant features.
- Regularization techniques prevent overfitting by adding penalties to complex models.
Why Is Quality Labeled Data Vital?
Accurate labels are crucial for effective supervised learning.
- Poor labels lead to incorrect model training and predictions.
- Human annotation or crowdsourcing can be used to generate labeled data.
What’s the Future of Supervised Learning?
Advancements in deep learning and larger datasets drive progress.
- Neural networks and deep learning tackle complex problems.
- Availability of big data contributes to more accurate models.
Python Code Examples
Example 1: Linear Regression
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic data
X = np.random.rand(100, 1)
y = 3 * X + 2 + np.random.randn(100, 1)
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
predictions
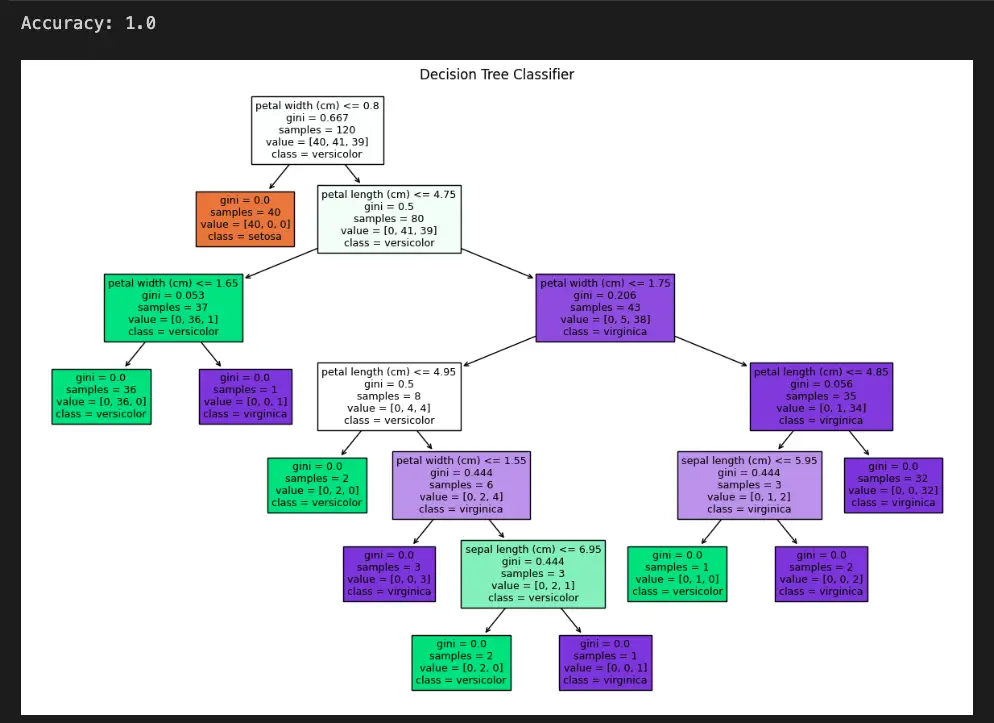
Example 2: Decision Tree Classifier with Plot_tree
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import plot_tree
# Load the iris dataset
data = load_iris()
X = data.data
y = data.target
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the classifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
# Make predictions
predictions = classifier.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)
# Plot the decision tree
plt.figure(figsize=(15, 10))
plot_tree(classifier, feature_names=data.feature_names, class_names=data.target_names, filled=True)
plt.title("Decision Tree Classifier")
plt.show()
Useful Python Libraries for Supervised Learning
- scikit-learn: Linear Regression, Decision Trees, Random Forest, Support Vector Machines, K-Nearest Neighbors, Gradient Boosting, etc.
- tensorflow: High-level neural network APIs for classification tasks.
- keras: Built on top of TensorFlow, provides user-friendly APIs for creating and training neural networks.
- pytorch: Offers tensors and dynamic computation graphs, suitable for building custom neural network architectures.
- xgboost: Gradient boosting framework for classification problems.
- lightgbm: Another gradient boosting framework optimized for speed and efficiency.
- catboost: Specialized gradient boosting library that handles categorical features well.
- pandas: Data manipulation and preprocessing, handling data in tabular format.
- numpy: Numerical operations and array handling, essential for numerical data processing.
- matplotlib: Data visualization, useful for plotting graphs and charts.
- seaborn: Built on top of Matplotlib, provides higher-level interfaces for creating attractive visualizations.
- scipy: Offers various statistical and optimization tools useful for preprocessing and analysis.
- statsmodels: Statistical modeling library for hypothesis testing, linear models, and more.
- sklearn.preprocessing: Preprocessing techniques like scaling, encoding, and feature extraction.
- sklearn.model_selection: Tools for cross-validation, hyperparameter tuning, and model selection.
Relevant Supervised Learning Topics
| Entity | Properties |
|---|---|
| Main Entity | Algorithm that learns from labeled data |
| Training Data | Labeled examples used to train the model |
| Features | Input variables used to make predictions |
| Labels | Output or target values to be predicted |
| Model | Learned representation of the data |
| Supervision | Providing correct answers during training |
Datasets Useful for Supervised Learning
1. Iris Dataset
# Python example
from sklearn.datasets import load_iris
# Load the iris dataset
data = load_iris()
X = data.data
y = data.target
2. Breast Cancer Wisconsin (Diagnostic) Dataset
# Python example
from sklearn.datasets import load_breast_cancer
# Load the breast cancer dataset
data = load_breast_cancer()
X = data.data
y = data.target
3. Boston Housing Dataset
# Python example
from sklearn.datasets import load_boston
# Load the Boston housing dataset
data = load_boston()
X = data.data
y = data.target
4. Wine Recognition Dataset
# Python example
from sklearn.datasets import load_wine
# Load the wine recognition dataset
data = load_wine()
X = data.data
y = data.target
Important Concepts in Supervised Learning
- Data Labeling
- Training Data and Testing Data
- Features and Feature Engineering
- Labels and Target Variables
- Model Selection
- Loss Functions
- Overfitting and Underfitting
- Cross-Validation
- Hyperparameter Tuning
- Metrics for Model Evaluation
To Know Before You Learn Supervised Learning?
- Understanding of basic machine learning concepts
- Familiarity with Python programming
- Understanding of data types and structures
- Basic statistics knowledge (mean, median, standard deviation)
- Knowledge of data preprocessing techniques
- Understanding of linear algebra (vectors, matrices)
- Familiarity with calculus (derivatives, gradients)
- Knowledge of different types of data (numerical, categorical)
- Basic concepts of model evaluation and validation
- Understanding of overfitting and underfitting
What’s Next?
- Unsupervised Learning
- Clustering Algorithms
- Dimensionality Reduction
- Semi-Supervised Learning
- Ensemble Methods
- Neural Networks and Deep Learning
- Natural Language Processing
- Time Series Analysis
- Reinforcement Learning
- Model Deployment and Production
- Advanced Model Evaluation Techniques
Sources
- scikit-learn.org/stable/supervised_learning.html">Scikit-Learn Documentation on Supervised Learning
- Towards Data Science – A Comprehensive Guide to Supervised Learning
- Machine Learning Mastery – Introduction to Supervised Learning
- Coursera – Supervised Learning
- Kaggle – Introduction to Supervised Learning
- Wikipedia – Supervised Learning
- Stanford University CS229 – Supervised Learning
- UCI Machine Learning Repository – Supervised Learning Datasets
- MIT OpenCourseWare – Introduction to Deep Learning
Conclusion
Supervised learning forms the foundation of many machine learning applications.
- It relies on labeled data to train models for accurate predictions.
- Understanding its concepts and challenges is essential for successful implementation.
