
Welcome to a comprehensive guide on Scikit-Learn’s MinMaxScaler in preprocessing.
This Scikit-learn scaler is a fundamental tool that helps standardize numerical data within a specific range, making it suitable for machine learning algorithms that are sensitive to feature scaling.
In this article, we’ll explore the key concepts, benefits, and how to use MinMaxScaler effectively.
Introduction to MinMaxScaler
MinMaxScaler is a preprocessing technique provided by Scikit-Learn that scales and transforms features in a dataset to a specified range, typically between 0 and 1. This scaling is particularly useful for machine learning algorithms that require features to have similar ranges to prevent certain features from dominating the learning process. MinMaxScaler can help improve the performance and convergence of models.
Important Concepts
Before delving into the usage of MinMaxScaler, it’s important to understand these key concepts:
- Feature Scaling: The process of transforming features so that they all have a similar scale, preventing some features from dominating others.
- Normalization: MinMaxScaler performs normalization by scaling features to a specified range, usually between 0 and 1.
- Data Transformation: MinMaxScaler transforms original feature values into scaled values while maintaining the data’s relative relationships.
Using MinMaxScaler
Using MinMaxScaler is straightforward:
- Create an instance of MinMaxScaler using
MinMaxScaler(). - Fit the scaler to your dataset using
fit(). - Transform the dataset using
transform()to scale the features.
Benefits of MinMaxScaler
MinMaxScaler offers several benefits:
- Preserves Relationships: MinMaxScaler maintains the relative relationships between feature values after scaling.
- Applicable to Various Algorithms: It’s suitable for algorithms sensitive to feature scaling, like k-nearest neighbors and neural networks.
- Improves Convergence: Scaling can help models converge faster during training.
Examples of MinMaxScaler
Explore MinMaxScaler through various examples:
- Scaling features in a dataset containing different ranges of values.
- Applying MinMaxScaler to a dataset with various machine learning algorithms.
- Comparing model performance before and after using MinMaxScaler.
With this knowledge of MinMaxScaler, you’ll be equipped to effectively preprocess your data and improve the performance of your machine learning models.
Python Code Examples
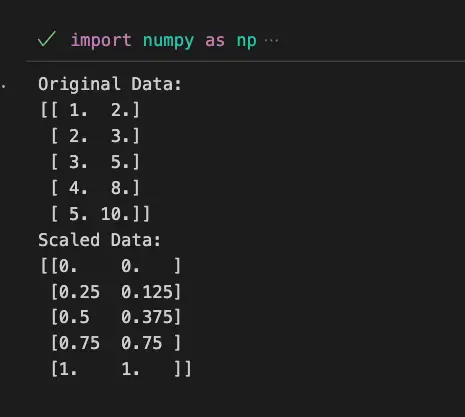
Example 1: Using MinMaxScaler with Scikit-Learn
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# Create a dataset
data = np.array([[1.0, 2.0], [2.0, 3.0], [3.0, 5.0], [4.0, 8.0], [5.0, 10.0]])
# Initialize MinMaxScaler
scaler = MinMaxScaler()
# Fit and transform the data
scaled_data = scaler.fit_transform(data)
print("Original Data:")
print(data)
print("Scaled Data:")
print(scaled_data)
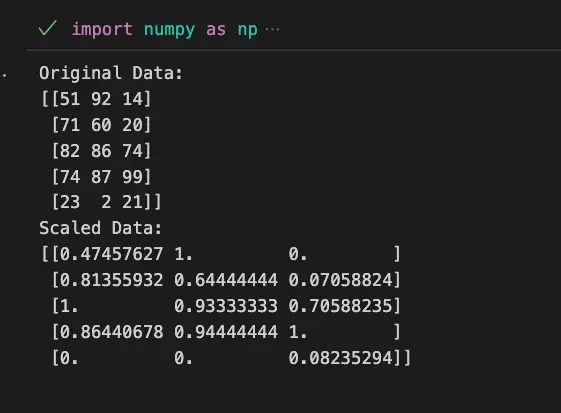
Example 2: Applying MinMaxScaler to a Dataset
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# Create a random dataset
np.random.seed(42)
data = np.random.randint(0, 100, size=(5, 3))
# Initialize MinMaxScaler
scaler = MinMaxScaler()
# Fit and transform the data
scaled_data = scaler.fit_transform(data)
print("Original Data:")
print(data)
print("Scaled Data:")
print(scaled_data)
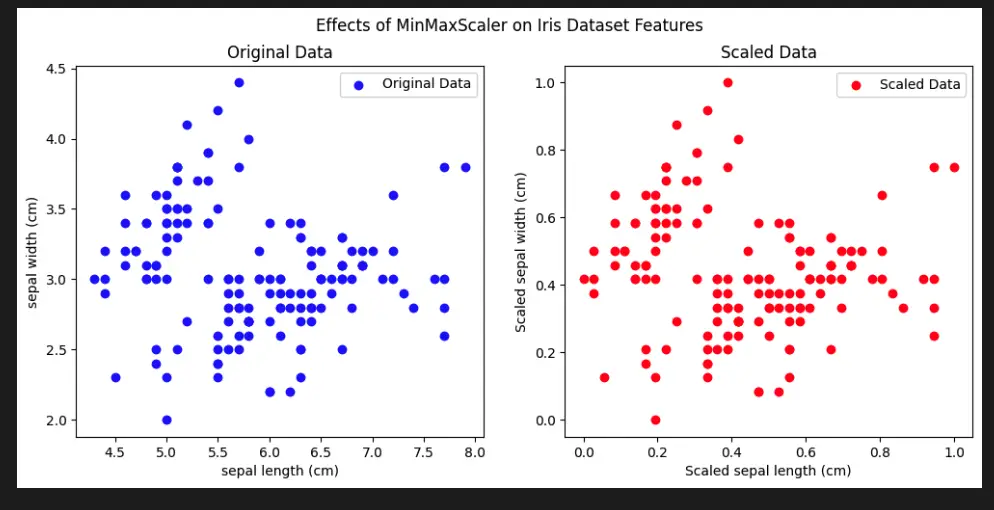
Visualize Scikit-Learn Preprocessing MinMaxScaler with Python
To visually understand the effects of the Scikit-Learn Preprocessing MinMaxScaler, we can use the famous Iris dataset. This dataset consists of three different species of iris flowers, each with four features (sepal length, sepal width, petal length, and petal width).
Let’s create a scatter plot to visualize the original and scaled features using MinMaxScaler.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
# Load the Iris dataset
iris = load_iris()
X = iris.data
feature_names = iris.feature_names
# Initialize MinMaxScaler
scaler = MinMaxScaler()
# Scale the features
scaled_X = scaler.fit_transform(X)
# Create subplots for original and scaled data
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
# Plot original data
axs[0].scatter(X[:, 0], X[:, 1], c='blue', label='Original Data')
axs[0].set_title('Original Data')
axs[0].set_xlabel(feature_names[0])
axs[0].set_ylabel(feature_names[1])
# Plot scaled data
axs[1].scatter(scaled_X[:, 0], scaled_X[:, 1], c='red', label='Scaled Data')
axs[1].set_title('Scaled Data')
axs[1].set_xlabel(f'Scaled {feature_names[0]}')
axs[1].set_ylabel(f'Scaled {feature_names[1]}')
# Add legend
axs[0].legend()
axs[1].legend()
# Set overall title
plt.suptitle('Effects of MinMaxScaler on Iris Dataset Features')
# Show the plots
plt.show()
Important Concepts in Scikit-Learn Preprocessing MinMaxScaler
- Feature Scaling
- Normalization
- Data Transformation
- Scaling Range
- Uniform Distribution
To Know Before You Learn Scikit-Learn Preprocessing MinMaxScaler
- Basic understanding of data preprocessing in machine learning
- Familiarity with different types of feature scaling techniques
- Knowledge of data normalization and its importance
- Understanding of data transformation and its impact on model performance
- Familiarity with Scikit-Learn library and its usage in machine learning tasks
What’s Next?
After learning about Scikit-Learn Preprocessing MinMaxScaler, you can explore more advanced topics in data preprocessing and feature engineering, which are crucial for building effective machine learning models. Here are some topics often taught after learning about MinMaxScaler:
- Z-score normalization using StandardScaler
- Handling missing data and imputation techniques
- One-hot encoding and categorical feature preprocessing
- Principal Component Analysis (PCA) for dimensionality reduction
- Feature selection methods to choose relevant features
- Advanced techniques like RobustScaler, PowerTransformer, and QuantileTransformer
Additionally, you can delve into applying these preprocessing techniques in various machine learning algorithms and exploring their impact on model performance and interpretability.
Relevant Entities
| Entity | Properties |
|---|---|
| MinMaxScaler | Scaler provided by Scikit-Learn for feature scaling and normalization. |
| Feature Scaling | Process of transforming features to have similar scales. |
| Normalization | Scaling features to a specified range, often between 0 and 1. |
| Data Transformation | Process of converting original feature values to scaled values while maintaining relationships. |
| Scaling Range | Typically between 0 and 1, helps prevent feature dominance. |
| Feature Values | Numerical values representing different features in a dataset. |
Sources
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html" target="_blank" rel="noreferrer noopener">Scikit-Learn Documentation: MinMaxScaler
- Analytics Vidhya: A Comprehensive Guide to Feature Scaling
- Towards Data Science: All About Feature Scaling
- Medium: Why Data Normalization is Necessary for Machine Learning Models
Conclusion
The MinMaxScaler provided by Scikit-Learn’s preprocessing module is a powerful tool for transforming features in a dataset to a common scale. By rescaling features to a specified range, it ensures that the machine learning algorithms are not biased towards features with larger magnitudes. This preprocessing technique is particularly useful when working with algorithms that are sensitive to feature scales, such as k-nearest neighbors and support vector machines.
Through this article, we’ve explored the essential concepts of MinMaxScaler, its application in standardizing data, and its benefits in improving the performance of machine learning models. By incorporating MinMaxScaler into your preprocessing pipeline, you can achieve more stable and accurate results in your machine learning projects.
Whether you’re handling numerical data, working on classification or regression tasks, or aiming to improve the efficiency of your machine learning algorithms, the MinMaxScaler is a valuable addition to your toolkit. By following best practices and experimenting with different scaling techniques, you’ll be well-equipped to create robust and reliable machine learning models.
