
Discover how Scikit-Learn’s preprocessing module offers the scale function for data scaling.
 scale() in MAtplotlib" class="wp-image-2244"/>
scale() in MAtplotlib" class="wp-image-2244"/>Understanding Scaling in Machine Learning
Data scaling is a vital preprocessing step that standardizes feature values, enhancing model performance.
Exploring Scikit-Learn Preprocessing Scale
The scale function in Scikit-Learn applies Z-score normalization to scale features.
Key Aspects of Scale
- Standardization: Transforming features to have zero mean and unit variance.
- Z-Score: Calculating the z-score of each feature’s value.
- Centering and Scaling: Separating mean centering and variance scaling steps.
Benefits of Scaling
- Improved Model Convergence: Scaled data helps algorithms converge faster.
- Comparable Features: Features with different scales can be compared more effectively.
- Enhanced Performance: Scaling can lead to better model accuracy and generalization.
Applying Scale
- Import the module: Import the scale function from sklearn.preprocessing.
- Prepare your data: Ensure your dataset is ready for scaling.
- Apply scaling: Use the scale function to transform your data.
- Proceed with modeling: Utilize the scaled data for training and evaluating your machine learning models.
Considerations and Limitations
- Data Characteristics: Understand how scaling affects different types of features.
- Impact on Interpretation: Scaled data might require adjustments in interpretation.
- Feature Importance: Scaling can affect feature importance rankings.
Python code Examples
Example 1: Scaling a Dataset using Scikit-Learn scale
import numpy as np
from sklearn.preprocessing import scale
# Create sample data
data = np.array([[1.0, 2.0],
[2.0, 3.0],
[3.0, 4.0]])
# Scale the data
scaled_data = scale(data)
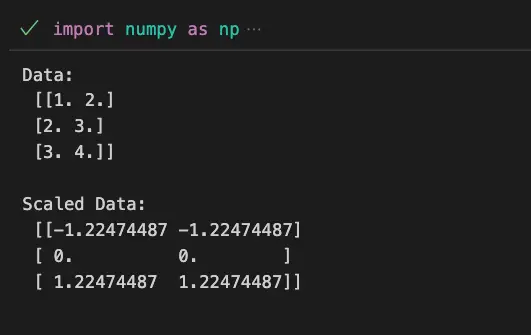
print(f'Data:\n {data}\n')
print(f'Scaled Data:\n {scaled_data}\n')In this example, the scale function from Scikit-Learn is used to scale a sample dataset by applying Z-score normalization.
Example 2: Scaling a Specific Feature
import numpy as np
from sklearn.preprocessing import scale
# Create sample data
data = np.array([[1.0, 2.0],
[2.0, 3.0],
[3.0, 4.0]])
# Scale the second feature
scaled_feature = scale(data[:, 1])
print(f'Data:\n {data}\n')
print(f'Scaled Feature:\n {scaled_feature}\n')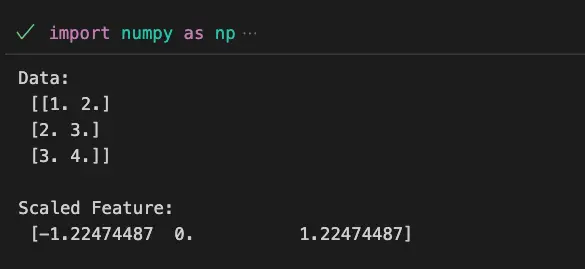
Visualize Scikit-Learn Preprocessing scale with Python
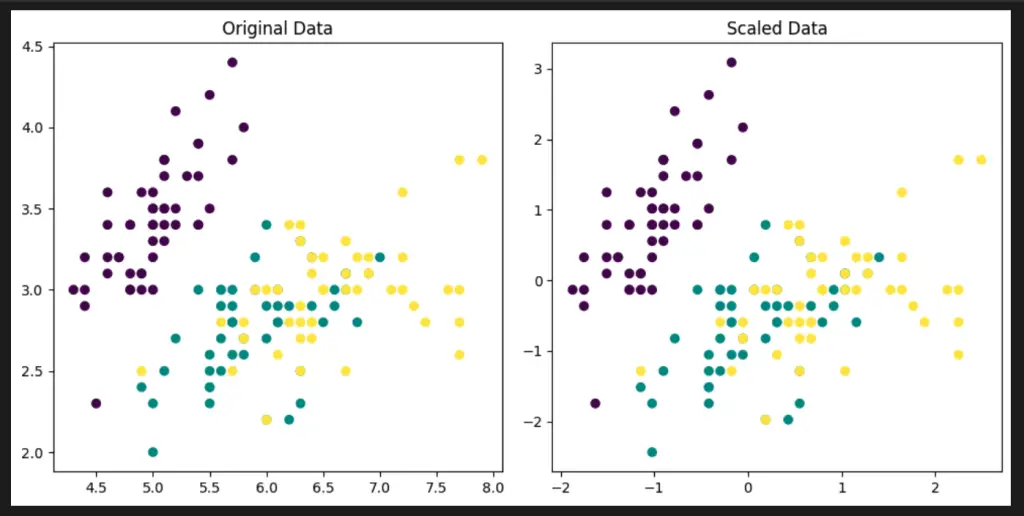
To visualize the Scikit-Learn Preprocessing scale functionality, we can use a built-in dataset from Scikit-Learn and visualize the scaled data using Matplotlib.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import scale
# Load the Iris dataset
iris = load_iris()
X = iris.data
# Scale the features
scaled_X = scale(X)
# Visualize the scaled data
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].scatter(X[:, 0], X[:, 1], c=iris.target)
axs[0].set_title("Original Data")
axs[1].scatter(scaled_X[:, 0], scaled_X[:, 1], c=iris.target)
axs[1].set_title("Scaled Data")
plt.tight_layout()
plt.show()
In this code example, we load the Iris dataset and use the scale function to scale the features. We then create a scatter plot to visualize the original and scaled data side by side using Matplotlib.
scale() in MAtplotlib" class="wp-image-2244"/>This example demonstrates how to scale a specific feature within a dataset using the scale function.
Important Concepts in Scikit-Learn Preprocessing scale
- Data Scaling
- Z-Score Normalization
- Standardization
- Feature Variance
- Feature Comparability
- Model Performance
To Know Before You Learn Scikit-Learn Preprocessing scale
- Basic understanding of machine learning concepts and algorithms.
- Familiarity with feature engineering and preprocessing techniques.
- Knowledge of data normalization and standardization.
- Understanding of Z-score normalization and its benefits.
- Awareness of the role of scaled data in improving model performance.
- Experience with Python programming and the Scikit-Learn library.
What’s Next?
After learning about Scikit-Learn Preprocessing scale, you may find it beneficial to explore the following topics:
- Feature Selection: Learn how to select relevant features to improve model efficiency.
- Normalization Techniques: Explore other data normalization methods like Min-Max scaling.
- Principal Component Analysis (PCA): Dive into dimensionality reduction techniques for high-dimensional data.
- Model Evaluation: Enhance your knowledge of evaluating model performance using various metrics.
- Hyperparameter Tuning: Understand how to optimize model parameters for better results.
Relevant Entities
| Entities | Properties |
|---|---|
| scale | Scikit-Learn function for Z-score normalization |
| Data Scaling | Process of transforming feature values for modeling |
| Z-Score Normalization | Technique to scale features to zero mean and unit variance |
| Feature Standardization | Transforming features for easier comparison |
| Model Performance | Evaluation of model’s predictive ability |
| Feature Variance | Measure of feature value spread |
Sources:
- scikit-learn.org/stable/modules/preprocessing.html#standardization-or-mean-removal-and-variance-scaling">Scikit-Learn Documentation: Standardization
- standardscaler-and-minmaxscaler-transforms-in-python/">StandardScaler and MinMaxScaler Transforms in Python
Conclusion
Scikit-Learn Preprocessing Scale offers a straightforward way to scale your features, enhancing the performance of your machine learning models. By applying scaling, you can achieve improved model convergence, better feature comparability, and enhanced prediction accuracy.
