
Welcome to our article on Scikit-Learn Preprocessing MaxAbsScaler. In the realm of machine learning, preprocessing is a pivotal step in preparing your data for effective model training.
This Scikit-learn scaler, the MaxAbsScaler, allows you to scale your data while preserving the relationships between features.
In this article, we’ll delve into the intricacies of the MaxAbsScaler, its applications, and how it can contribute to the success of your machine learning projects.
Understanding MaxAbsScaler
MaxAbsScaler is a data preprocessing technique designed to scale features to a specific range while retaining their original relationships. It is particularly useful when dealing with sparse datasets or data that has a mix of positive and negative values. By using the MaxAbsScaler, you can ensure that your features are brought into a range of [-1, 1], making them suitable for various machine learning algorithms.
How MaxAbsScaler Works
The MaxAbsScaler operates by dividing each feature by the maximum absolute value of that feature across the entire dataset. This ensures that all values fall within the [-1, 1] range, without shifting the distribution of the data. As a result, your data’s relationships and characteristics remain intact, making it a reliable choice for scaling.
Benefits of Using MaxAbsScaler
- Preservation of Data Relationships: Unlike some other scaling techniques, MaxAbsScaler maintains the original relationships between features.
- Applicability to Sparse Data: MaxAbsScaler is well-suited for datasets with a large number of zero or sparse entries.
- Interpretability: Scaled features retain their interpretability, allowing you to understand the impact of the scaled data on your models.
When to Use MaxAbsScaler
Consider using MaxAbsScaler when you have features with varying ranges and distributions, and you want to ensure that the relationships between these features are preserved. This is especially useful when working with algorithms that are sensitive to feature scales, such as those based on distance metrics.
Applying MaxAbsScaler in Scikit-Learn
Implementing MaxAbsScaler in Scikit-Learn is straightforward. The library provides a user-friendly API that allows you to easily fit and transform your data using the MaxAbsScaler object. This enables you to seamlessly integrate the scaling process into your machine learning pipelines.
Python Code Examples
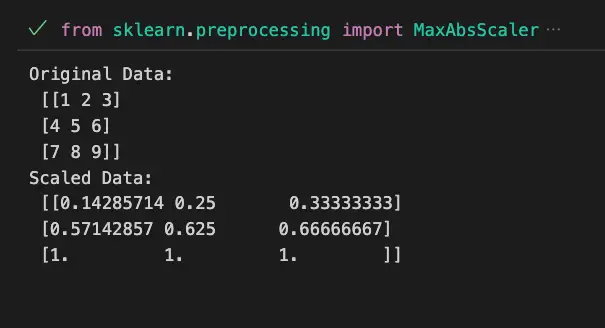
Example 1: Scaling Features using MaxAbsScaler
from sklearn.preprocessing import MaxAbsScaler
import numpy as np
# Sample data with different scales
data = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# Initialize MaxAbsScaler
scaler = MaxAbsScaler()
# Fit and transform the data
scaled_data = scaler.fit_transform(data)
print("Original Data:\n", data)
print("Scaled Data:\n", scaled_data)
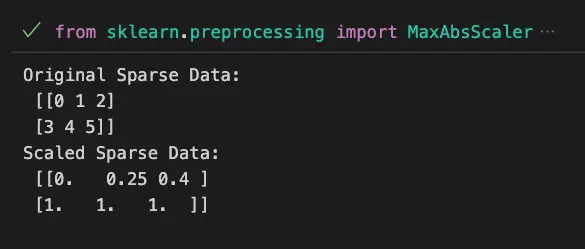
Example 2: Applying MaxAbsScaler to Sparse Data
from sklearn.preprocessing import MaxAbsScaler
from scipy.sparse import csr_matrix
# Sparse matrix example
sparse_data = csr_matrix([[0, 1, 2],
[3, 4, 5]])
# Initialize MaxAbsScaler for sparse data
sparse_scaler = MaxAbsScaler()
# Fit and transform sparse data
scaled_sparse_data = sparse_scaler.fit_transform(sparse_data)
print("Original Sparse Data:\n", sparse_data.toarray())
print("Scaled Sparse Data:\n", scaled_sparse_data.toarray())
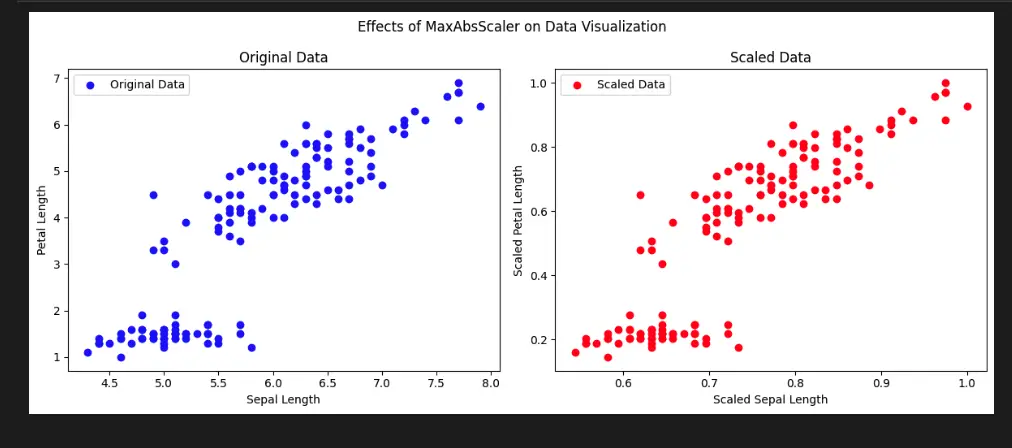
Visualize Scikit-Learn Preprocessing MaxAbsScaler with Python
To demonstrate the effects of the MaxAbsScaler on data visualization, we will use the built-in Iris dataset provided by Scikit-learn. We’ll focus on two features, sepal length and petal length, and visualize the scaled data using Matplotlib.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MaxAbsScaler
# Load the Iris dataset
iris = load_iris()
data = iris.data[:, [0, 2]] # Select sepal length and petal length
# Initialize MaxAbsScaler
scaler = MaxAbsScaler()
# Fit and transform the data
scaled_data = scaler.fit_transform(data)
# Create subplots for original and scaled data
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
# Plot original data
axs[0].scatter(data[:, 0], data[:, 1], c='blue', label='Original Data')
axs[0].set_title('Original Data')
axs[0].set_xlabel('Sepal Length')
axs[0].set_ylabel('Petal Length')
# Plot scaled data
axs[1].scatter(scaled_data[:, 0], scaled_data[:, 1], c='red', label='Scaled Data')
axs[1].set_title('Scaled Data')
axs[1].set_xlabel('Scaled Sepal Length')
axs[1].set_ylabel('Scaled Petal Length')
# Add legend
axs[0].legend()
axs[1].legend()
# Set overall title
plt.suptitle('Effects of MaxAbsScaler on Data Visualization')
# Show the plots
plt.tight_layout()
plt.show()
Important Concepts in Scikit-Learn Preprocessing MaxAbsScaler
- Data Scaling
- Feature Scaling
- Normalization
- Data Preprocessing
- Linear Transformation
- Scaling Techniques
- Feature Engineering
To Know Before You Learn Scikit-Learn Preprocessing MaxAbsScaler?
- Basic understanding of data preprocessing in machine learning.
- Familiarity with feature scaling techniques like Min-Max Scaling.
- Knowledge of how data scaling affects machine learning algorithms.
- Understanding of linear transformations and normalization techniques.
- Familiarity with Scikit-Learn library and its preprocessing module.
What’s Next?
After learning about Scikit-Learn Preprocessing MaxAbsScaler, you’ll likely move on to the following topics in machine learning:
- StandardScaler and RobustScaler: Explore other scaling techniques provided by Scikit-Learn to preprocess data.
- Feature Engineering: Learn about techniques to create new features from existing ones, improving model performance.
- Model Selection and Evaluation: Understand how to choose and evaluate machine learning algorithms.
- Model Tuning: Dive into hyperparameter tuning to optimize the performance of your machine learning models.
- Advanced Machine Learning Concepts: Explore more complex topics like ensemble methods, deep learning, and natural language processing.
Relevant Entities
| Entity | Properties |
|---|---|
| MaxAbsScaler | Scale features to [-1, 1] Preserve feature relationships Applicable to sparse data Retains interpretability Sensitive to feature scales |
| Data Preprocessing | Prepare data for machine learning Improve model performance Enhance algorithm sensitivity |
| Scikit-Learn | Machine learning library in Python Provides preprocessing tools Offers MaxAbsScaler implementation |
| Feature Scaling | Normalize feature values Prevent dominance of certain features Improve algorithm convergence |
| Machine Learning Pipelines | Sequence of data processing steps Integrate preprocessing and modeling Enhance code organization |
Sources:
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MaxAbsScaler.html" target="_blank" rel="noreferrer noopener">Scikit-Learn Documentation on MaxAbsScaler:
- Towards Data Science – Preprocessing with Scikit-Learn: A Complete and Comprehensive Guide
- Analytics Vidhya – A Comprehensive Guide to Feature Transformation and Scaling
- DataCamp – Preprocessing in Data Science: Centering, Scaling, and K-Nearest Neighbors
Conclusion
Scikit-Learn Preprocessing MaxAbsScaler is a valuable tool for ensuring your data is appropriately scaled for machine learning tasks. By preserving the relationships between features while scaling, MaxAbsScaler offers a powerful solution for improving the performance of various algorithms. Incorporating this technique into your preprocessing workflow can contribute to more accurate and reliable models.
We hope this article has provided you with a clear understanding of the MaxAbsScaler and its significance in the world of machine learning. Happy scaling!
