
Scikit-Learn provides a powerful set of preprocessing techniques to prepare your data for machine learning tasks.
Minmax_scale is one of the Scikit-learn’s scaling functions, which allows you to scale features to a specific range. In this article, we’ll explore the minmax_scale function, its benefits, and how it can enhance your machine learning pipelines.
 minmax_scale in Machine Learning" class="wp-image-2116"/>
minmax_scale in Machine Learning" class="wp-image-2116"/>What is minmax_scale?
minmax_scale is a preprocessing technique in Scikit-Learn that scales and transforms features to a specified range. It linearly scales the input features to fit within the given range, often between 0 and 1. This technique is particularly useful when features have different scales and you want to ensure that they are comparable.
How Does minmax_scale Work?
The minmax_scale function works by applying a linear transformation to each feature independently. The formula used for scaling is:
scaled_feature = (feature - min(feature)) / (max(feature) - min(feature))
This ensures that the scaled feature values fall within the specified range, preserving the relative relationships between data points.
Benefits of Using minmax_scale
- Preserves the relationships between data points.
- Helps prevent features with larger scales from dominating the learning process.
- Ensures that all features are on a comparable scale, which is important for algorithms sensitive to feature magnitudes.
How to Use minmax_scale
Using minmax_scale in Scikit-Learn is straightforward:
- Import the
preprocessingmodule from Scikit-Learn. - Create an instance of the
MinMaxScalerclass. - Fit the scaler to your data using the
fitmethod. - Transform your data using the
transformmethod.
When to Use minmax_scale
minmax_scale is especially useful in scenarios where:
- Features have different scales and magnitudes.
- Algorithms require input features to be on the same scale.
- You want to prevent features with larger values from dominating the learning process.
Python code Examples
Using MinMaxScaler with Scikit-Learn
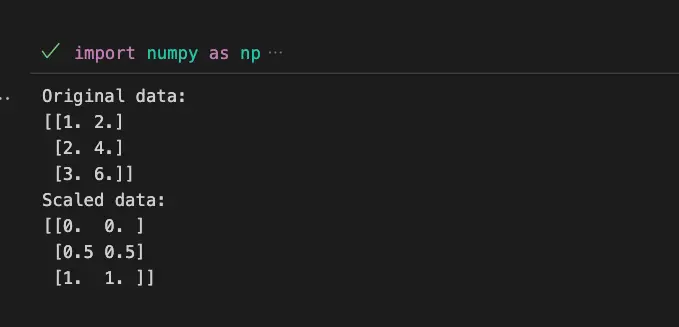
import numpy as np
from sklearn.preprocessing import minmax_scale
#Create a sample dataset
data = np.array([[1.0, 2.0],
[2.0, 4.0],
[3.0, 6.0]])
#Apply MinMaxScaler to scale the dataset
scaled_data = minmax_scale(data)
print("Original data:")
print(data)
print("Scaled data:")
print(scaled_data)
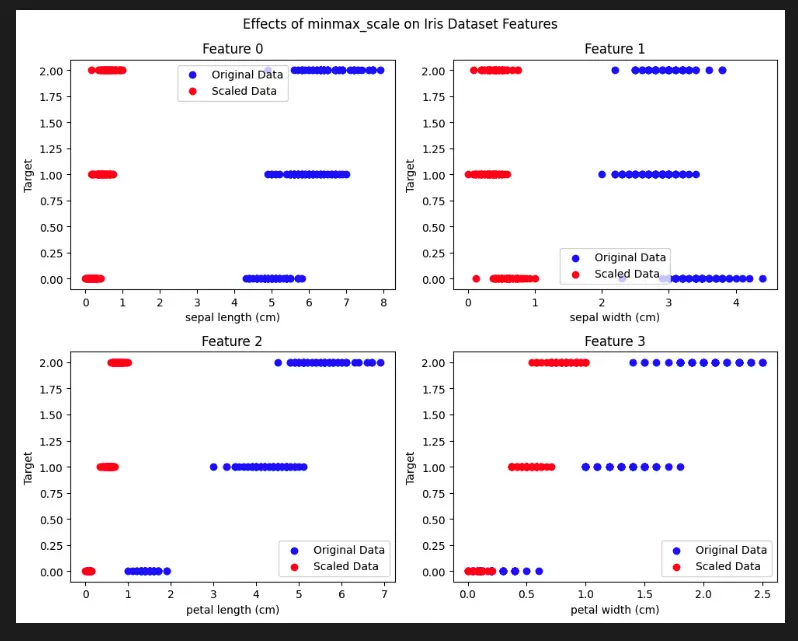
Visualize Scikit-Learn Preprocessing minmax_scale with Python
To demonstrate the effects of minmax_scale using the Matplotlib library, we can use the built-in Iris dataset from Scikit-learn. We’ll visualize the scaled features to observe the transformation.
import matplotlib.pyplot as plt
from sklearn.preprocessing import minmax_scale
from sklearn.datasets import load_iris
#Load the Iris dataset
iris = load_iris()
#Apply minmax_scale to the dataset
scaled_data = minmax_scale(iris.data)
#Create subplots for each feature
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
fig.suptitle('Effects of minmax_scale on Iris Dataset Features')
#Plot original and scaled data for each feature
for feature_idx, ax in enumerate(axs.ravel()):
ax.scatter(iris.data[:, feature_idx], iris.target, c='blue', label='Original Data')
ax.scatter(scaled_data[:, feature_idx], iris.target, c='red', label='Scaled Data')
ax.set_title(f'Feature {feature_idx}')
ax.set_xlabel(iris.feature_names[feature_idx])
ax.set_ylabel('Target')
ax.legend()
plt.tight_layout()
plt.show()
Important Concepts in Scikit-Learn Preprocessing minmax_scale
- Data Scaling and Normalization
- Feature Transformation
- Scaling Techniques
- Range of Values
- Feature Impact on Scaling
To Know Before You Learn Scikit-Learn Preprocessing minmax_scale
- Basic understanding of data preprocessing in machine learning
- Familiarity with different data scaling techniques
- Understanding of feature scaling and its importance
- Knowledge of Scikit-Learn library and its usage in Python
- Concepts of data distribution and normalization
What’s Next?
- Advanced feature engineering techniques
- Exploring other data preprocessing methods in Scikit-Learn
- Deeper understanding of normalization and its impact on different algorithms
- Introduction to dimensionality reduction techniques
- Application of preprocessing techniques in specific machine learning models
| Entity | Properties |
|---|---|
| Scikit-Learn Preprocessing minmax_scale | Scaling technique in Scikit-Learn |
| Features | Input variables or attributes of a dataset |
| Range | Specified interval to which features are scaled |
| Scaling | Transformation of feature values to fit within a range |
| Linear transformation | Mathematical operation applied to each feature independently |
| MinMaxScaler | Scikit-Learn class used to apply min-max scaling |
Sources
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.minmax_scale.html">Scikit-Learn Documentation – minmax_scale
- scale-and-sklearn-preproce">Stack Overflow – Difference between scale and minmax_scale
- scale-standardize-or-normalize-with-scikit-learn-6ccc7d176a02">Towards Data Science – Scale, Standardize, or Normalize with Scikit-Learn
- Machine Learning Mastery – How to Improve Neural Network Stability and Modeling Performance with Data Scaling
- Medium – Normalization vs Standardization: Quantitative Analysis
Conclusion
Scikit-Learn’s minmax_scale offers a simple yet effective way to preprocess your data and ensure that your features are on a comparable scale. By scaling features to a specified range, you can enhance the performance of your machine learning algorithms and achieve more accurate and robust results.
Remember that choosing the appropriate preprocessing technique depends on the characteristics of your data and the requirements of your machine learning tasks. minmax_scale is a valuable tool in your toolkit for feature scaling and preparing data for various machine learning models.
