
Scikit-Learn’s LabelBinarizer is one of the Binarizers used in Scikit-learn to assist machine learning projects in transforming categorical labels into a binary format. This binarization makes them suitable for various algorithms. Let’s delve into the details of what LabelBinarizer is and how it can be beneficial in preprocessing data.

What is Scikit-Learn Preprocessing LabelBinarizer?
LabelBinarizer is a preprocessing technique provided by Scikit-Learn that helps in transforming categorical labels into a binary representation, often referred to as one-hot encoding. It’s a straightforward yet essential step in preparing categorical data for machine learning algorithms.
Why Use LabelBinarizer?
When working with machine learning algorithms, many models require numerical input. However, categorical labels don’t directly fit these algorithms. LabelBinarizer simplifies this process by transforming categorical labels into binary vectors, where each class is represented as a separate binary column.
How Does LabelBinarizer Work?
LabelBinarizer works by transforming categorical labels into a binary matrix. Each label is replaced with a row containing 0s and a single 1 at the corresponding class column, indicating the presence of that class. This binary representation ensures that the transformed labels can be used as input for various machine learning algorithms.
When to Use LabelBinarizer?
LabelBinarizer is particularly useful when dealing with classification problems where categorical labels need to be converted into a format that algorithms can understand. It’s commonly used in scenarios such as multi-class classification tasks where class labels don’t have an inherent numerical relationship.
Benefits of LabelBinarizer
- Simple Transformation: LabelBinarizer offers a straightforward way to convert categorical labels into a binary matrix.
- Compatible with Algorithms: Transformed labels can be directly used with various machine learning algorithms.
- Scalability: LabelBinarizer can handle large datasets with multiple classes effectively.
How to Use LabelBinarizer?
Using LabelBinarizer is easy. Import the class from Scikit-Learn’s preprocessing module, create an instance, and then fit and transform your categorical labels. The result will be a binary matrix that you can use for training your machine learning models.
Python Code Examples
Example 1: Basic LabelBinarizer Usage
from sklearn.preprocessing import LabelBinarizer
#Sample categorical labels
labels = ['cat', 'dog', 'bird', 'cat', 'dog']
#Create a LabelBinarizer instance
binarizer = LabelBinarizer()
#Binarize the labels
binarized_labels = binarizer.fit_transform(labels)
print('Labels:\n',labels)
print('Binarized:\n',binarized_labels)

Example 2: Binarizing Multiple Classes
from sklearn.preprocessing import LabelBinarizer
#Sample categorical labels
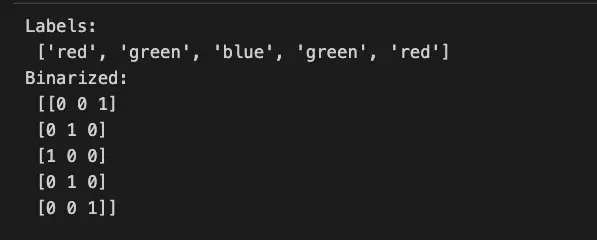
labels = ['red', 'green', 'blue', 'green', 'red']
#Create a LabelBinarizer instance
binarizer = LabelBinarizer()
#Binarize the labels
binarized_labels = binarizer.fit_transform(labels)
print('Labels:\n',labels)
print('Binarized:\n',binarized_labels)
Visualize LabelBinarizer with Python
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelBinarizer
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
species = iris.target_names[iris.target]
# Create a LabelBinarizer instance
binarizer = LabelBinarizer()
# Binarize the species labels
binarized_species = binarizer.fit_transform(species)
# Plot the effects of LabelBinarizer
plt.figure(figsize=(10, 6))
# Original species labels
plt.subplot(1, 2, 1)
plt.scatter(iris.data[:, 0], iris.data[:, 1], c=iris.target)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title('Original Species Labels')
# Binarized species labels
plt.subplot(1, 2, 2)
for class_idx in range(binarized_species.shape[1]):
plt.scatter(iris.data[:, 0], iris.data[:, 1], c=binarized_species[:, class_idx], label=f'Class {class_idx}')
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title('Binarized Species Labels')
plt.legend()
plt.tight_layout()
plt.show()
Important Concepts in Scikit-Learn Preprocessing LabelBinarizer
- One-Hot Encoding
- Multi-class Classification
- Binary Classification
- Label Encoding
- Transforming Categorical Data
To Know Before You Learn Scikit-Learn Preprocessing LabelBinarizer
- Basic understanding of data preprocessing in machine learning.
- Familiarity with categorical variables and their representation.
- Understanding of encoding techniques like one-hot encoding and label encoding.
- Knowledge of classification problems and different types of classification tasks.
- Basic knowledge of the Scikit-Learn library and its functions.
What’s Next?
After learning about Scikit-Learn Preprocessing LabelBinarizer, you might want to explore the following topics to enhance your understanding of data preprocessing and related machine learning concepts:
- Handling imbalanced datasets and techniques for dealing with class imbalance.
- Feature scaling and normalization methods to bring different features to a common scale.
- Feature selection and dimensionality reduction techniques to improve model efficiency.
- Exploring other preprocessing techniques in Scikit-Learn, such as StandardScaler, MinMaxScaler, and PolynomialFeatures.
- Understanding more advanced topics in machine learning, such as model selection, hyperparameter tuning, and ensemble methods.
By diving into these topics, you can build a solid foundation in data preprocessing and machine learning that will enable you to tackle a wide range of real-world problems.
Relevant entities
| Entity | Properties |
|---|---|
| LabelBinarizer | Transforms categorical labels into binary matrix |
| Categorical Labels | Non-numerical class labels |
| Binary Matrix | Matrix with binary representation of labels |
| Machine Learning Algorithms | Models that require numerical input |
| One-Hot Encoding | Binary representation of categorical data |
| Classification Problems | Tasks where class labels need to be predicted |
Sources:
Here are some popular pages and resources to learn more about Scikit-Learn Preprocessing LabelBinarizer:
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelBinarizer.html" target="_blank" rel="noreferrer noopener">Scikit-Learn Documentation – Official documentation for Scikit-Learn’s LabelBinarizer class.
- scikit-learn" target="_blank" rel="noreferrer noopener">Stack Overflow – Browse questions and answers related to Scikit-Learn preprocessing and LabelBinarizer.
- DataCamp Tutorial – A tutorial on preprocessing techniques, including LabelBinarizer, with practical examples.
- Machine Learning Mastery – A guide to one-hot encoding techniques, which are closely related to label binarization.
Exploring these resources will provide you with valuable insights into using Scikit-Learn Preprocessing LabelBinarizer effectively in your machine learning projects.
Conclusion
LabelBinarizer is a versatile preprocessing technique that simplifies the transformation of categorical labels into a binary format. It plays a crucial role in making categorical data compatible with machine learning algorithms, enhancing the accuracy and effectiveness of your models.
