
Linear Discriminant Analysis (LDA) is a powerful statistical technique used for classification and dimensionality reduction in the field of machine learning. It is a supervised learning algorithm, meaning that it requires labeled data to build its model.
Introduction to LDA
LDA is a method of finding a linear combination of features that characterizes or separates two or more classes of objects or events. The main objective of LDA is to find a projection of the data that maximizes the separation between the classes while minimizing the variation within each class. This projection can then be used to classify new samples that fall within the same feature space.
The LDA algorithm is closely related to Principal Component Analysis (PCA), which is another dimensionality reduction technique. The main difference between the two methods is that LDA is a supervised learning algorithm, while PCA is an unsupervised learning algorithm. This means that PCA doesn’t make use of any class labels, whereas LDA uses class labels to determine the best projection of the data.
Why learn Linear Discriminant Analysis (LDA)?
- LDA is a powerful classification algorithm used in various fields, such as computer vision, image recognition, and natural language processing.
- It helps to reduce the dimensionality of data while preserving most of the relevant information, which makes it suitable for high-dimensional datasets.
- LDA provides a clear visualization of the separability between different classes in the data, making it easier to understand and interpret the results.
- It is a relatively simple algorithm to implement, and there are many resources available online to learn about it.
Learning about LDA can provide you with a deeper understanding of the underlying concepts of machine learning algorithms. It can also expand your skillset, making you a more competitive candidate in the job market. Overall, LDA is a valuable tool for any data scientist or machine learning practitioner to have in their toolkit.
Mathematical Details
The LDA algorithm works by first calculating the mean vectors for each class in the dataset. It then calculates the scatter matrix, which is a measure of the variance within each class. The goal of LDA is to find a projection of the data that maximizes the between-class scatter matrix and minimizes the within-class scatter matrix.
This is done by calculating the eigenvectors and eigenvalues of the scatter matrix, and then choosing the eigenvectors with the largest eigenvalues as the projection matrix. These eigenvectors define the direction in which the data should be projected to maximize the separation between the classes.
Applications
LDA is commonly used in image recognition, face recognition, and other computer vision applications where dimensionality reduction and classification are required. It is also used in bioinformatics and genetics research to classify and analyze large datasets.
Limitations
Like all machine learning algorithms, LDA has its limitations. One of the main limitations is that it assumes that the data is normally distributed, and that the classes have the same covariance matrix. If these assumptions are not met, the performance of the algorithm can suffer. Additionally, LDA is sensitive to outliers and can be affected by the curse of dimensionality if the number of features is too high relative to the number of samples.
Python code Examples
Linear Discriminant Analysis (LDA) on Iris Dataset
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
iris = load_iris()
X = iris.data
y = iris.target
lda = LinearDiscriminantAnalysis()
lda.fit(X, y)
predicted = lda.predict(X)
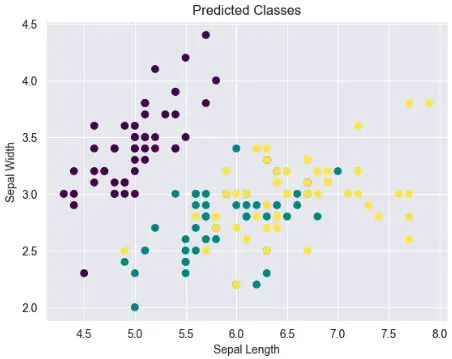
# Plot the predicted classes
plt.scatter(X[:, 0], X[:, 1], c=predicted, cmap='viridis')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Predicted Classes')
plt.show()Stackoverflow Example: Linear Discriminant Analysis (LDA) with Python
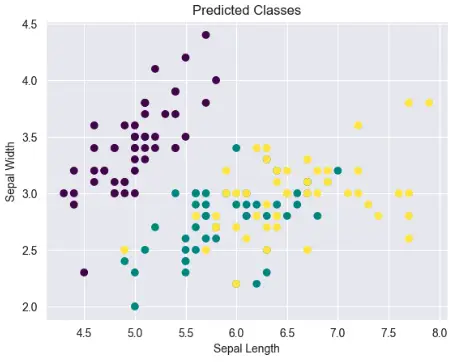
Hyperparameter Tuning: Fine Tune LDA’s Hyperparameters
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import GridSearchCV
iris = load_iris()
X = iris.data
y = iris.target
lda = LinearDiscriminantAnalysis()
params = {'solver': ['svd', 'lsqr', 'eigen'], 'shrinkage': [None, 'auto', 0.1, 0.5, 0.9]}
clf = GridSearchCV(lda, params, cv=5)
clf.fit(X, y)
predicted = clf.predict(X)
# Plot the predicted classes
plt.scatter(X[:, 0], X[:, 1], c=predicted, cmap='viridis')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Predicted Classes')
plt.show()
Show Best Scores and Parameters
print("Best score: ", clf.best_score_)
print("Best parameters: ", clf.best_params_)
Best score: 0.9800000000000001
Best parameters: {'shrinkage': None, 'solver': 'svd'}Visualizing and Evaluating LDA Results on Iris Dataset
We will now create a multi-class confusion matrix as a heatmap.
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import seaborn as sns
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
predicted = lda.predict(X_test)
cm = confusion_matrix(y_test, predicted)
sns.heatmap(cm, annot=True)
Stackoverflow Example: How to display text next to a imshow figure in matplotlib

Important Concepts in Linear Discriminant Analysis (LDA)
- Supervised Learning
- Classification
- Dimensionality Reduction
- Covariance Matrix
- Eigenvalues and Eigenvectors
- Singular Value Decomposition (SVD)
- Maximum Separation
- Projection
- Decision Boundary
- Class Prior Probability
Useful Python Libraries for Linear Discriminant Analysis (LDA)
- scikit-learn: LinearDiscriminantAnalysis(), GridSearchCV(), train_test_split(), confusion_matrix()
- numpy: cov(), eig()
- pandas: DataFrame(), read_csv()
- matplotlib: scatter(), subplots(), imshow()
- seaborn: heatmap()
Datasets useful for Linear Discriminant Analysis (LDA)
Here are some datasets that are commonly used to learn Linear Discriminant Analysis (LDA) in machine learning:
Iris dataset
The Iris dataset is a popular dataset in machine learning, which consists of 150 samples of iris flowers, each with four features (sepal length, sepal width, petal length, and petal width). It is commonly used for classification tasks and is often used as an example to demonstrate LDA.
# Loading Iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
# Creating feature matrix X and target vector y
X = iris.data
y = iris.target
Wine dataset
The Wine dataset is another popular dataset in machine learning, which consists of 178 samples of wines, each with 13 features (including alcohol content, malic acid, ash, etc.). It is also commonly used for classification tasks and is often used to demonstrate LDA.
# Loading Wine dataset
from sklearn.datasets import load_wine
wine = load_wine()
# Creating feature matrix X and target vector y
X = wine.data
y = wine.target
Breast cancer dataset
The Breast cancer dataset is a dataset that contains measurements of breast cancer tumors, with features including the radius, texture, perimeter, area, etc. It is also commonly used for classification tasks and is often used to demonstrate LDA.
# Loading Breast cancer dataset
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
# Creating feature matrix X and target vector y
X = breast_cancer.data
y = breast_cancer.target
These datasets can be easily loaded in Python using the scikit-learn library, which is a popular machine learning library in Python.
To Know Before You Learn Linear Discriminant Analysis (LDA)?
Before learning about Linear Discriminant Analysis (LDA), it is recommended to have a good understanding of the following topics:
- Statistics: A basic understanding of statistical concepts like mean, variance, covariance, and probability distributions is essential to understand LDA.
- Linear Algebra: Knowledge of linear algebra concepts like vectors, matrices, eigenvectors, and eigenvalues is important to understand the mathematical basis of LDA.
- Classification: Understanding the basics of classification algorithms like logistic regression and Naive Bayes is useful as LDA is also a classification algorithm.
- Python: Familiarity with the Python programming language and its scientific computing libraries such as NumPy, Pandas, and Scikit-learn is important as LDA is commonly implemented using these libraries in Python.
What’s Next?
- Feature Engineering
- Quadratic Discriminant Analysis (QDA): QDA is a similar classification algorithm to LDA but allows for more flexibility in the covariance matrix, which can lead to improved accuracy in certain cases.
- Principal Component Analysis (PCA): PCA is a technique used for dimensionality reduction that can be used in conjunction with LDA to preprocess data and improve classification accuracy.
- Support Vector Machines (SVMs): SVMs are a popular classification algorithm that can be used for linear and nonlinear classification tasks and are often used as an alternative to LDA.
- Deep Learning: Deep learning is a subfield of machine learning that involves training artificial neural networks to perform complex tasks, and is often used in advanced applications such as computer vision and natural language processing.
Relevant Entities
| Entity | Properties |
|---|---|
| Linear Discriminant Analysis (LDA) | Supervised learning, classification, dimensionality reduction |
| Covariance Matrix | Measures the relationship between variables in a dataset |
| Eigenvalues | Measures the amount of variance captured by each eigenvector |
| Eigenvectors | Used to transform data into a new space where the most important information is preserved |
| PCA | Unsupervised learning, dimensionality reduction |
| Machine Learning | The study of algorithms and statistical models that enable computer systems to improve performance on a specific task through experience |
Frequently Asked Questions
LDA is a supervised learning method used for classification and dimensionality reduction.
In feature transformation, LDA is used for feature extraction while PCA is used for feature reduction.
The goal of LDA is to find a projection of the data that maximizes the separation between the classes.
LDA assumes that the classes have the same covariance matrix and are normally distributed.
LDA is a probabilistic model, while logistic regression is a discriminative model.
LDA can be used to reduce the dimensionality of data by projecting it onto a lower-dimensional space that preserves the class separability.
Conclusion
Linear Discriminant Analysis (LDA) is a powerful and widely used technique in machine learning for classification and dimensionality reduction. It is a supervised learning algorithm that uses class labels to find the best projection of the data, and is closely related to Principal Component Analysis (PCA). While LDA has its limitations, it remains a valuable tool in the machine learning toolbox.
Sources
- Linear discriminant analysis – Wikipedia
- scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html" target="_blank" rel="noreferrer noopener">LinearDiscriminantAnalysis – Scikit-learn
- Linear Discriminant Analysis for Machine Learning – Machine Learning Mastery
- Linear Discriminant Analysis in Python – Towards Data Science
- A Guide to Linear Discriminant Analysis (LDA) – Analytics Vidhya
- Understanding Linear Discriminant Analysis in Python – DataCamp
- Linear Discriminant Analysis (LDA) Explained and Implemented in Python – Medium
- Linear Discriminant Analysis (LDA): How to Use LDA for Feature Selection – Built In
- What is the difference between LDA and PCA? – Analytics Vidhya
- ML | Linear Discriminant Analysis (LDA) – GeeksforGeeks
