
Feature extraction is an essential part of machine learning.
It involves selecting and transforming the relevant data into a set of features that can be used to train a machine learning model.
In other words, feature extraction is the process of converting raw data into a set of features that can be used to make predictions.
There are many techniques for feature extraction, each with its own advantages and disadvantages. In this article, we will explore some of the most commonly used techniques for feature extraction.
Below is one of example of what we will achieve in this guide by vectorizing text to numerical data.
Feature Extraction Techniques
Principal Component Analysis (PCA)
PCA is a popular technique for dimensionality reduction and feature extraction. It involves transforming a set of correlated variables into a set of uncorrelated variables, known as principal components. PCA is useful for reducing the dimensionality of a dataset while retaining most of the information.
Linear Discriminant Analysis (LDA)
LDA is a technique for feature extraction that is used to find the linear combinations of features that can best separate different classes of data. LDA is useful for reducing the dimensionality of a dataset while maximizing the separation between classes.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE is a nonlinear technique for dimensionality reduction and feature extraction. It is particularly useful for visualizing high-dimensional data. t-SNE maps high-dimensional data into a low-dimensional space while preserving the local structure of the data.
Autoencoders
Autoencoders are a type of neural network that can be used for feature extraction. They work by encoding the input data into a lower-dimensional representation, and then decoding it back into its original form. Autoencoders are useful for learning a compact representation of high-dimensional data.
Python code examples
Using CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# Example text documents
corpus = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create CountVectorizer object
vectorizer = CountVectorizer()
# Fit and transform the text data into feature vectors
X = vectorizer.fit_transform(corpus)
# Print the feature names and feature vectors
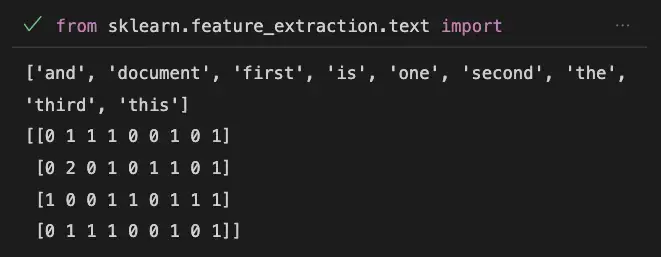
print(vectorizer.get_feature_names())
print(X.toarray())
This code uses the CountVectorizer class from Scikit-learn to convert text data into feature vectors.
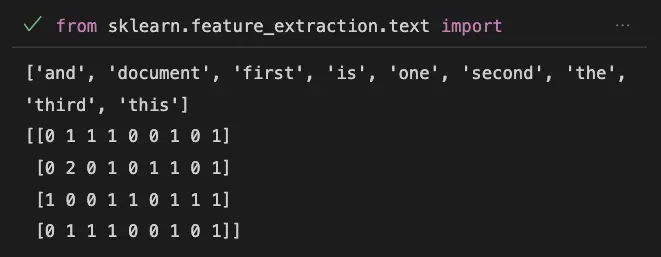
The fit_transform() method of the CountVectorizer class is used to fit the model to the data and transform it into a feature matrix.
The resulting feature matrix X is a sparse matrix, which can be converted to a dense matrix using the toarray() method.
Useful Python Libraries for Feature extraction
- scikit-learn: feature_extraction module, such as CountVectorizer, TfidfVectorizer, and DictVectorizer.
- gensim: models such as Word2Vec and Doc2Vec.
- NLTK: modules such as nltk.collocations and nltk.sentiment.
- OpenCV: modules such as cv2.goodFeaturesToTrack and cv2.FeatureDetector.
Datasets useful for Feature extraction
Image Classification – MNIST
from tensorflow.keras.datasets import mnist
# Load the MNIST dataset
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Flatten the images into a 1D array
X_train = X_train.reshape((X_train.shape[0], 28 * 28)).astype('float32')
X_test = X_test.reshape((X_test.shape[0], 28 * 28)).astype('float32')
Text Classification – 20 Newsgroups
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
# Load the 20 Newsgroups dataset
newsgroups_train = fetch_20newsgroups(subset='train')
# Convert the raw text data into TF-IDF vectors
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(newsgroups_train.data)
Relevant entities
| Entity | Properties |
|---|---|
| Feature | Characteristic of the input data used for prediction |
| Feature Vector | Numerical representation of a set of features |
| Dimensionality Reduction | Technique to reduce the number of features |
| PCA | Linear technique for dimensionality reduction |
| t-SNE | Non-linear technique for dimensionality reduction |
Important Concepts in Feature extraction
- Feature representation
- Dimensionality reduction
- Unsupervised feature learning
- Feature selection
- Signal processing
Frequently Asked Questions
Feature extraction is the process of selecting, extracting, and transforming relevant information from raw data into a set of meaningful and informative features that can be used for machine learning algorithms.
Feature extraction is important because it enables machine learning algorithms to work with high-dimensional and complex data by transforming the data into a set of features that capture the important characteristics of the data.
The common techniques used for feature extraction are Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), Independent Component Analysis (ICA), Feature Scaling, and Feature Selection.
PCA is a technique used for feature extraction that reduces the dimensionality of a dataset while retaining most of the important information. It does this by finding the principal components, which are the directions of maximum variance in the dataset.
LDA is a technique used for feature extraction that aims to find a linear combination of features that maximally separate the classes in a dataset. It is commonly used in classification problems.
ICA is a technique used for feature extraction that separates a multivariate signal into independent, non-Gaussian components. It is commonly used in signal processing and image analysis.
Feature selection is the process of selecting a subset of relevant features from a larger set of features. It is important for improving the performance of machine learning algorithms and reducing the computational complexity of the algorithms.
Conclusion
Feature extraction is an essential part of machine learning. It is the process of converting raw data into a set of features that can be used to train a machine learning model.
There are many techniques for feature extraction, each with its own advantages and disadvantages. Some of the most commonly used techniques include PCA, LDA, t-SNE, and autoencoders.
If you are interested in learning more about feature extraction, you can refer to the following resources:
