
Word2Vec is a game-changing technique in the field of natural language processing that enables machines to comprehend human language in a more human-like way. In this article, we’ll explore the fundamentals of Word2Vec, how it operates, and its myriad applications.
What is Word2Vec?
At its core, Word2Vec is a technique for transforming words into vectors, which are then utilized by machine learning algorithms to comprehend language. These vectors are organized in such a way that words with comparable meanings are positioned closely together in the vector space.
How Does Word2Vec Work?
The technique works by training a neural network to forecast a word based on its neighboring words. The neural network may be constructed utilizing one of two architectures: Continuous Bag of Words (CBOW) or Skip-Gram.
CBOW forecasts the central word based on the surrounding words, while Skip-Gram forecasts the surrounding words based on the central word. Through adjusting the weights between the input and output layers, the neural network is trained to ensure that the predicted word is as close as feasible to the actual word.
What are Word Embeddings?
Word embeddings are a type of representation for words in a numerical form that captures semantic relationships and meanings between words. They are used to transform words into dense vectors of real numbers, where similar words are represented by vectors that are closer together in the vector space.
Traditional methods of representing words, such as one-hot encoding, are sparse and lack semantic information. Word embeddings, on the other hand, provide a continuous and distributed representation that encodes semantic and contextual relationships among words. These embeddings are often learned from large text corpora using machine learning techniques like Word2Vec, GloVe (Global Vectors for Word Representation), and FastText.
Applications of Word2Vec
The applications of Word2Vec are extensive and varied. One of the most popular applications is in text classification, where it is utilized to classify text based on the meaning of words. It is also utilized in sentiment analysis, where it can determine the sentiment of a piece of text by analyzing the meaning of the words used.
Another important application of Word2Vec is in machine translation, where it can assist in improving the accuracy of translations by identifying the correct meanings of words. It is also employed in recommendation systems, where it can recommend products or services based on the meaning of the user’s queries.
What is CBOW?
CBOW (Continuous Bag of Words) is a model architecture within the Word2Vec framework, which is used to learn word embeddings from large text corpora. CBOW aims to predict a target word based on its surrounding context words. It is a type of neural network architecture that leverages the context of words to generate meaningful word embeddings.
How does CBOW work?
- Context Window: CBOW operates by defining a context window around each target word. The context window is a fixed number of words to the left and right of the target word. For example, if the context window size is set to 2, then the context for the word “apple” in the sentence “I like to eat apples” would be [“I”, “like”, “eat”].
- Input and Output Representations: CBOW treats each context window as input and the target word as the output. The input is represented as a one-hot encoded vector, where only the entry corresponding to the context word is set to 1 and all others are set to 0. The output is also represented as a one-hot encoded vector for the target word.
- Hidden Layer: The input layer feeds into a hidden layer, which is a fully connected layer. The weights connecting the input layer and the hidden layer are the word embeddings for the context words.
- Word Embeddings: The weights of the hidden layer are actually the word embeddings that are learned during the training process. These embeddings capture the semantic relationships between words based on their co-occurrence patterns.
- Output Layer: The hidden layer then connects to the output layer, which is another fully connected layer. The output layer’s size is equal to the vocabulary size, and it represents the probability distribution over all words in the vocabulary.
- Loss Function: During training, CBOW minimizes the difference between the predicted probability distribution (output of the neural network) and the actual probability distribution (one-hot encoded vector for the target word). This is typically done using the softmax function and the cross-entropy loss.
- Training: As the CBOW model is trained on a large corpus, the word embeddings in the hidden layer start to capture the semantic relationships between words. Words with similar contexts will have similar embeddings, and these embeddings can then be used to measure word similarity or perform other NLP tasks.
CBOW is efficient and particularly suited for scenarios where the frequency of words in the corpus is relatively high. It works well for generating word embeddings for infrequent words as well, as they can benefit from the context of their surrounding more frequent words.
What is Skip-Gram in Word2Vec
Skip-gram is a word embedding algorithm that is part of the Word2Vec framework for learning distributed representations of words. It is designed to learn word embeddings by predicting the context words surrounding a given target word. Skip-gram is particularly effective at capturing the semantic relationships and similarities between words, making it a popular choice for various natural language processing tasks.
Here’s how the skip-gram algorithm works:
- Input Data Preparation: Skip-gram takes a large corpus of text data as input. The text is tokenized into words, and each word is assigned a unique index.
- Creating Training Pairs: For each target word in the corpus, skip-gram generates training pairs. The target word is paired with its surrounding context words within a fixed window size. The window size determines how many context words are considered for each target word.
- Word Embeddings Initialization: Before training, each word in the vocabulary is represented by an initial random embedding vector. These embeddings will be learned and updated during training.
- Model Architecture: The skip-gram model consists of an input layer, an embedding layer, and an output layer. The input to the model is the one-hot encoded vector representation of the target word. The embedding layer transforms the input vector into a continuous vector representation (embedding) in a lower-dimensional space. The output layer predicts the probability distribution of context words given the target word.
- Training Objective: The objective of skip-gram is to maximize the likelihood of observing the context words given the target word. In other words, the model aims to predict the context words based on the target word.
- Learning Embeddings: The training process involves adjusting the embedding vectors using backpropagation and gradient descent to minimize the negative log-likelihood of observing the actual context words. This optimization process adjusts the embeddings so that words that share similar context tend to have similar vector representations.
- Semantic Relationships: After training, the embedding vectors capture semantic relationships between words. Words that often appear in similar contexts will have similar embeddings in the vector space. This allows the embeddings to capture word similarities, analogies, and other linguistic patterns.
- Inference: Once the skip-gram model is trained, you can use the learned embeddings for downstream tasks such as text classification, sentiment analysis, machine translation, and more.
Skip-gram tends to perform well on large and diverse text corpora. It’s particularly effective in capturing the meaning of rare words and their relationships to other words. While it requires more training time compared to the Continuous Bag of Words (CBOW) model, skip-gram is often preferred when working with complex language models or tasks that demand a deeper understanding of word semantics.
Python Code Examples
Getting the Most Similar Words using Word2Vec
Word2Vec has the most_similar() method that allows use to find the most similar words from a corpus aof sentences.
import gensim.downloader as api
from gensim.models import Word2Vec
# Load the Text8 dataset
dataset = api.load("text8")
# Train a CBOW Word2Vec model
model = Word2Vec(sentences=dataset, sg=0, window=5, vector_size=100, min_count=5, workers=4)
# Get the most similar words to a given word
target_word = "king"
similar_words = model.wv.most_similar(target_word)
similar_words
In this example, we load the “text8” dataset using the api.load function from gensim.downloader. We then train a CBOW Word2Vec model on the dataset. Next, we choose a target_word (“king” in this case) and use the most_similar method of the model’s word vectors (model.wv) to get the most similar words and their similarity scores.
The code then prints out the most similar words along with their similarity scores. You can replace the target_word with any other word from the vocabulary to find its most similar words based on the trained Word2Vec model.

Plotting Word2Vec
import gensim.downloader as api
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Load the Text8 dataset
dataset = api.load("text8")
# Train a CBOW model
model_cbow = Word2Vec(sentences=dataset, sg=0, window=5, vector_size=100, min_count=5, workers=4)
target_words = ["king", "queen", "man", "woman"]
# Get the word vectors for the specified words
word_vectors = [model_cbow.wv[word] for word in target_words]
# Reduce dimensionality using PCA for visualization
pca = PCA(n_components=2)
word_vectors_pca = pca.fit_transform(word_vectors)
# Plot word vectors and annotations
plt.figure(figsize=(10, 8))
for i, word in enumerate(target_words):
plt.annotate(word, (word_vectors_pca[i, 0], word_vectors_pca[i, 1]), fontsize=10)
plt.arrow(0, 0, word_vectors_pca[i, 0], word_vectors_pca[i, 1], head_width=0.1, head_length=0.1, fc='blue', ec='blue')
plt.title('Word Vectors and Annotations')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid()
plt.axhline(y=0, color='black', linewidth=0.5)
plt.axvline(x=0, color='black', linewidth=0.5)
plt.show()
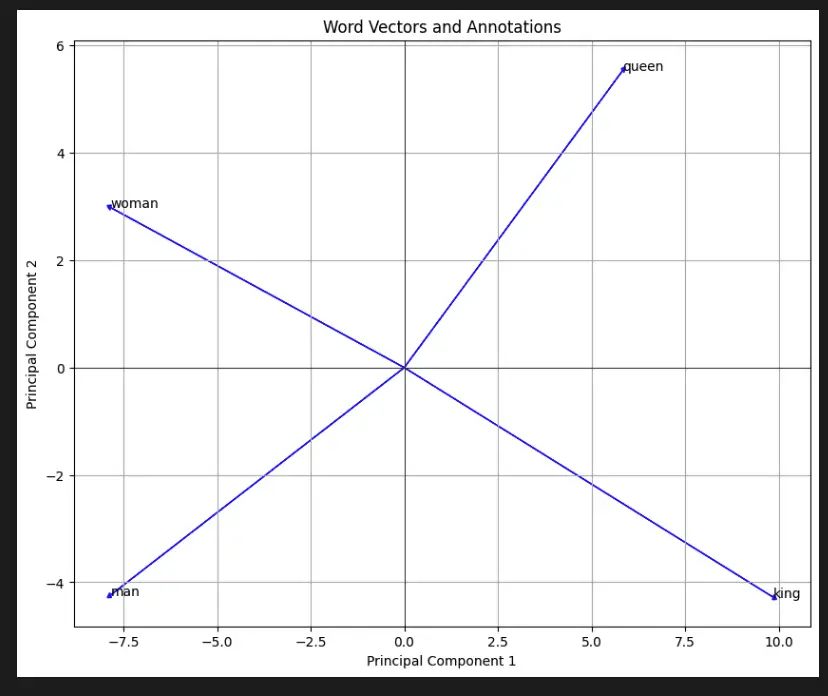
This code demonstrates the use of Word2Vec embeddings to visualize word vectors in a 2D space using PCA (Principal Component Analysis) for dimensionality reduction. Here’s how it works step by step:
- The code imports necessary libraries:
gensim.downloaderfor loading the “text8” dataset,Word2Vecfromgensim.modelsfor training a CBOW model,matplotlib.pyplotfor visualization, andPCAfromsklearn.decompositionfor dimensionality reduction. - The “text8” dataset is loaded using
api.load("text8"). This dataset contains a large amount of text that will be used to train the Word2Vec model. - A CBOW model is trained using the loaded dataset. The model’s parameters are set, including
sg=0to indicate using the CBOW architecture,window=5for the context window size,vector_size=100for the dimensionality of word vectors,min_count=5to ignore words with a low frequency, andworkers=4for multi-threading. - The
target_wordslist contains the words “king,” “queen,” “man,” and “woman” for which we want to visualize the word vectors. - For each word in
target_words, the code retrieves the corresponding word vector from the trained Word2Vec model and stores it in theword_vectorslist. - PCA is applied to reduce the dimensionality of the word vectors to 2D.
- The code creates a plot using
matplotlib.pyplot, where each word vector is represented as a point on the plot. For each word, an annotation is added to label the point, and an arrow is drawn from the origin (0,0) to the point, indicating the direction of the vector. - The plot’s title, labels, grid lines, and axes are configured, and the plot is displayed using
plt.show().
Overall, this code generates a plot that shows the positions of the word vectors for the specified words in a 2D space, allowing us to visualize their relationships and similarities.
Word2Vec Methods
Word2Vec is a neural network-based approach to learn word embeddings, which represent words as vectors in a continuous space. The Word2Vec algorithm has two variations: Continuous Bag of Words (CBOW) and Skip-gram. The Gensim library provides an implementation of both variations, along with other useful methods for working with word embeddings. Here are some of the most commonly used Word2Vec methods in Gensim:
Word2Vec()
Word2Vec(sentences, size, window, min_count, workers)This class is used to train a Word2Vec model on a corpus of sentences. sentences is a list of tokenized sentences, size is the dimensionality of the word vectors, window is the maximum distance between the current and predicted word within a sentence, min_count is the minimum frequency of a word to be included in the vocabulary, and workers is the number of threads to use for training the model.
most_similar()
most_similar(positive=None, negative=None, topn=10, restrict_vocab=None, indexer=None) This method returns the most similar words to a given word or set of words. positive is a list of words that are considered to have a positive influence on the result, negative is a list of words that are considered to have a negative influence on the result, topn is the number of similar words to return, restrict_vocab is an optional integer to limit the search to a subset of the vocabulary, and indexer is an optional object that is used to retrieve the index of a word in the vocabulary.
similarity(w1, w2)
This method returns the cosine similarity between two words. w1 and w2 are the two words to compare.
most_similar_cosmul()
most_similar_cosmul(positive=None, negative=None, topn=10, restrict_vocab=None, indexer=None) This method returns the most similar words to a given word or set of words using a multiplicative combination of the input word vectors. positive, negative, topn, restrict_vocab, and indexer have the same meaning as in most_similar().
- wv[word] – This method returns the vector representation of a word. word is the word to look up.
- wv.vocab – This method returns a dictionary of all the words in the vocabulary and their associated frequency.
train()
train(sentences, total_examples=None, total_words=None, epochs=None, start_alpha=None, end_alpha=None, word_count=0, queue_factor=2, report_delay=1.0, compute_loss=False, callbacks=(), **kwargs)This method is used to continue training an existing Word2Vec model on new sentences. sentences is a list of tokenized sentences, total_examples is the total number of sentences in the corpus, total_words is the total number of words in the corpus, epochs is the number of training epochs, start_alpha is the initial learning rate, end_alpha is the final learning rate, word_count is the number of words that have already been trained, queue_factor is the ratio of input queue size to worker thread count, report_delay is the delay between progress reports, compute_loss is a flag to indicate whether to compute the training loss, and callbacks is a list of callback functions to call after each epoch. Other keyword arguments can be used to set various training parameters.
Both most_similar() and most_similar_cosmul() are methods of the Word2Vec model in Gensim that are used to find the most similar words to a given word. However, there are some differences between the two methods in terms of the output they produce.
most_similar() returns the top-N most similar words to a given word as a list of tuples. The first element in each tuple is the similar word, and the second element is its similarity score.
Useful Python Libraries for Word2Vec
There are several Python libraries that can be used for Word2Vec in machine learning. Here are some of the most useful ones:
- Gensim
- NLTK
- spaCy
- Tensorflow
Gensim
This is a popular open-source library for natural language processing (NLP) tasks. It provides an implementation of Word2Vec algorithm as well as other models like Doc2Vec, FastText, etc. Gensim offers simple and efficient APIs for building, training and using Word2Vec models. Some useful methods include:
- Word2Vec: to train Word2Vec models.
- KeyedVectors: to load and use pre-trained Word2Vec models.
- most_similar: to find most similar words based on the trained model.
- similarity: to calculate the similarity between two words based on the trained model.
NLTK
This is another popular NLP library that provides tools for text processing and analysis. It also provides an implementation of Word2Vec algorithm. Some useful methods include:
- word_tokenize: to tokenize sentences into words.
- sent_tokenize: to tokenize text into sentences.
- Word2Vec: to train Word2Vec models.
- similarity: to calculate the similarity between two words based on the trained model.
spaCy
his is a modern NLP library that provides state-of-the-art models for various NLP tasks. It also provides an implementation of Word2Vec algorithm. Some useful methods include:
- load: to load pre-trained Word2Vec models.
- similarity: to calculate the similarity between two words based on the loaded model.
- vocab.vectors.most_similar: to find most similar words based on the loaded model.
TensorFlow
This is a popular open-source machine learning library that provides tools for building and training various machine learning models. It also provides an implementation of Word2Vec algorithm. Some useful methods include:
- tf.nn.embedding_lookup: to lookup embeddings for a set of input words.
- tf.nn.nce_loss: to calculate the negative sampling loss for training the Word2Vec model.
- tf.nn.embedding_softmax: to convert embeddings to softmax weights.
These are just a few examples of the Python libraries and methods that can be used for Word2Vec in machine learning.
Datasets useful for Word2Vec
There are several datasets that can be used for Word2Vec in machine learning. Here are some of the most useful ones:
Wikipedia Dump
This dataset contains the complete text from all articles in different languages available in Wikipedia. It is a rich source of natural language text that can be used to train Word2Vec models. To load this dataset in Python, you can use the following code:
import gensim.downloader as api
# Download Wikipedia dump dataset
dataset = api.load("wiki-320k-raw") # Choose the desired size of the dataset
Text8
This is a small but popular dataset used for testing Word2Vec models. It consists of a cleaned and preprocessed version of a large corpus of English text. To load this dataset in Python, you can use the following code:
from gensim.test.utils import datapath
# Download Text8 dataset
text8_path = datapath("text8")
dataset = gensim.models.word2vec.Text8Corpus(text8_path)
These are just a few examples of the datasets that can be used for Word2Vec in machine learning. There are many more datasets available that can be used for this purpose.
Relevant Entities
| Entity | Properties |
|---|---|
| Word2Vec | Transforms words into vectors for machine learning. |
| Neural network | Trained to forecast a word based on its neighboring words. |
| Continuous Bag of Words (CBOW) | Architecture used to forecast the central word based on surrounding words. |
| Skip-Gram | Architecture used to forecast the surrounding words based on the central word. |
| Text classification | Classifies text based on the meaning of words. |
| Sentiment analysis | Determines the sentiment of a piece of text by analyzing the meaning of the words used. |
| Machine translation | Assists in improving the accuracy of translations by identifying the correct meanings of words. |
| Recommendation systems | Recommends products or services based on the meaning of the user’s queries. |
Important Concepts in Word2Vec
- Neural networks
- Backpropagation algorithm
- Activation functions
- Embeddings
- Continuous Bag of Words (CBOW)
- Skip-Gram
- Training data
- Word similarity
- Cosine similarity
- Dimensionality reduction
To Know Before You Learn Word2Vec?
- Python programming language
- Machine learning fundamentals
- Linear algebra
- Probability and statistics
- Natural Language Processing (NLP)
- Understanding of text data preprocessing techniques
- Familiarity with neural networks and their applications in NLP
- Experience with deep learning libraries such as TensorFlow or PyTorch
- Experience with data visualization tools
- Comfortable with command-line interface and code version control
What’s Next?
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM)
- Convolutional Neural Networks (CNNs)
- Sequence-to-sequence models
- Attention models
- Transformer models
- Advanced NLP applications such as question-answering and text summarization
- Transfer learning techniques for NLP
- Domain-specific language models such as BERT, GPT-2, and ELMO
- Multi-lingual NLP and cross-lingual transfer learning
Sources:
- https://en.wikipedia.org/wiki/Word2vec
- word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b">https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
- word2vec">https://www.tensorflow.org/tutorials/text/word2vec
- word2vec.html">https://radimrehurek.com/gensim/models/word2vec.html
Conclusion
Word2Vec has transformed the way in which machines comprehend human language. By converting words into vectors and then positioning them in a vector space, machines can now capture the meaning of words more effectively. This has far-reaching implications in natural language processing, including text classification, sentiment analysis, machine translation, and recommendation systems. As natural language processing continues to evolve, Word2Vec is certain to remain a critical tool for enabling machines to understand human language more accurately and efficiently.
