
Welcome to this article that delves into the world of Scikit-Learn preprocessing scalers. Scaling is a vital step in preparing data for machine learning, and Scikit-Learn provides various scaler techniques to achieve this.
What Are Scikit-Learn Preprocessing Scalers?
Scikit-Learn preprocessing scalers are tools designed to standardize or normalize numerical features in a dataset.
Why Use Scalers in Preprocessing?
Scalers ensure that numerical features are on a similar scale, preventing some features from dominating others during model training.
Types of Scikit-Learn Preprocessing Scalers
Scikit-Learn offers several scaler methods, each with distinct characteristics:
- StandardScaler: Standardizes features by removing mean and scaling to unit variance.
- MinMaxScaler: Scales features to a specified range (usually 0 to 1).
- RobustScaler: Scales features using median and interquartile range to handle outliers.
How to Choose the Right Scaler?
Choosing the appropriate scaler depends on the nature of your data and the requirements of your machine learning algorithm.
Scaler Comparison: Advantages, Disadvantages, and Best Use Cases
| Scaler | Advantages | Disadvantages | Best Use Cases |
|---|---|---|---|
| StandardScaler | Handles normally distributed data well. Preserves the original distribution and does not change the shape. | Sensitive to outliers and may be affected by them. Not suitable for data with non-Gaussian distributions. | Data with normally distributed features. Algorithms sensitive to feature scaling, such as SVM, k-NN, and neural networks. |
| MinMaxScaler | Scales features to a specified range, preserving relationships. Does not distort the original distribution. | Sensitive to outliers, which can affect scaling. Does not handle data with extreme outliers effectively. | Features with unknown distribution or varying scales. Algorithms that require features on a similar scale. |
| RobustScaler | Handles data with outliers effectively. Uses the median and interquartile range for scaling. | May distort the original distribution if outliers are present. Not suitable for normally distributed data without outliers. | Data with outliers or skewed distributions. Algorithms sensitive to outliers, like linear regression and k-means. |
Python Examples With Different Sklearn Scalers
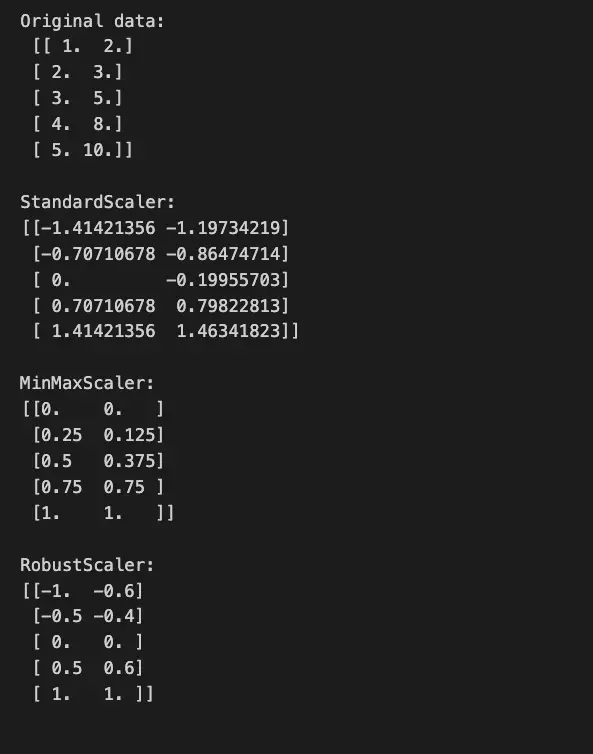
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# Create a dataset
data = np.array([[1.0, 2.0], [2.0, 3.0], [3.0, 5.0], [4.0, 8.0], [5.0, 10.0]])
# Apply different scalers
scalers = {
'StandardScaler': StandardScaler(),
'MinMaxScaler': MinMaxScaler(),
'RobustScaler': RobustScaler(),
}
print(f"Original data:\n {data}\n")
# Print the scaled data for each scaler
for scaler_name, scaler in scalers.items():
scaled_data = scaler.fit_transform(data)
print(f"{scaler_name}:\n{scaled_data}\n")
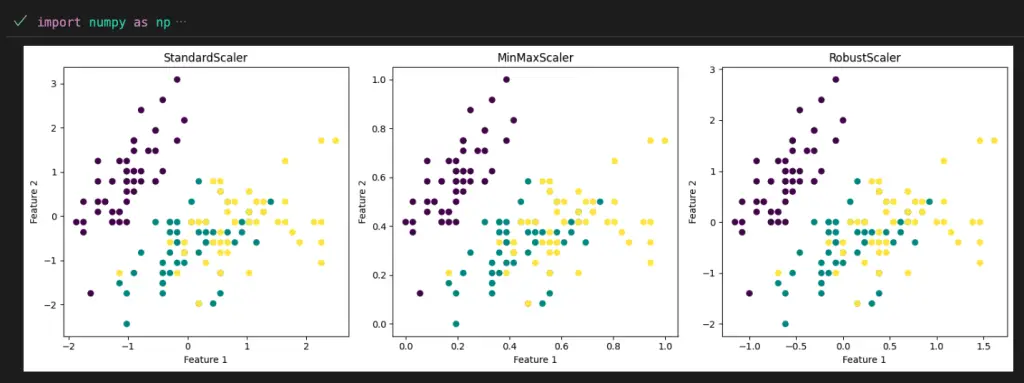
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# Load the Iris dataset
iris = load_iris()
X = iris.data
# Apply different scalers
scalers = {
'StandardScaler': StandardScaler(),
'MinMaxScaler': MinMaxScaler(),
'RobustScaler': RobustScaler()
}
scaled_data = {scaler_name: scaler.fit_transform(X) for scaler_name, scaler in scalers.items()}
# Create subplots to compare the effects of different scalers
fig, axes = plt.subplots(1, len(scalers), figsize=(15, 5))
for ax, (scaler_name, scaled_features) in zip(axes, scaled_data.items()):
ax.scatter(scaled_features[:, 0], scaled_features[:, 1], c=iris.target)
ax.set_title(scaler_name)
ax.set_xlabel("Feature 1")
ax.set_ylabel("Feature 2")
plt.tight_layout()
plt.show()
Benefits of Scaling
Scaling has several advantages in machine learning:
- Enhances convergence and performance of optimization algorithms.
- Improves the stability of machine learning models.
- Helps algorithms that rely on distance metrics or gradients.
Considerations and Impact on Algorithms
Scaling can influence the behavior of machine learning algorithms:
- Some algorithms are sensitive to feature scaling, like k-nearest neighbors.
- Others, such as tree-based models, are relatively unaffected by scaling.
- Deep learning models often require input features to be scaled.
Important Concepts in Scikit-Learn Scalers
- Feature Scaling
- Data Distribution
- Normalization
- Standardization
- Scaling Methods
- Outlier Impact
- Algorithm Sensitivity
- Robust Scaling
- Min-Max Scaling
- Z-Score Scaling
To Know Before You Learn Scikit-Learn Scalers?
- Understanding of Feature Scaling
- Basic Python Programming Skills
- Familiarity with Scikit-Learn Library
- Knowledge of Data Preprocessing
- Concept of Data Distribution
- Awareness of Data Transformation
- Importance of Normalization and Standardization
- Experience with Descriptive Statistics
- Understanding of Algorithm Sensitivity
- Familiarity with Machine Learning Algorithms
What’s Next?
Once you’ve grasped the concepts of Scikit-Learn scalers, you’ll likely find these topics valuable to further your understanding of data preprocessing and machine learning:
- Feature Selection and Dimensionality Reduction
- Hyperparameter Tuning
- Model Evaluation and Selection
- Ensemble Learning Methods
- Advanced Machine Learning Algorithms
- Time Series Analysis and Forecasting
- Natural Language Processing (NLP)
- Deep Learning and Neural Networks
- Reinforcement Learning
- Machine Learning in Real-world Scenarios
Exploring these topics will help you build a strong foundation in machine learning and enable you to tackle more complex challenges.
Relevant Entities
| Entity | Properties |
|---|---|
| StandardScaler | Standardizes features by removing mean and scaling to unit variance. Handles normally distributed data. Useful for algorithms sensitive to feature scaling. |
| MinMaxScaler | Scales features to a specified range (usually 0 to 1). Preserves relationships between data points. Effective for algorithms requiring features on similar scales. |
| RobustScaler | Scales features using median and interquartile range. Handles data with outliers effectively. Useful for algorithms sensitive to outliers. |
| fit | Method to compute scaling parameters. Used for fitting the scaler on training data. Calculates mean, variance, or other necessary values. |
| transform | Method to apply scaling to new data. Used for transforming test or validation data. Applies learned scaling parameters to new samples. |
Conclusion
Scikit-Learn preprocessing scalers are essential tools for standardizing and normalizing numerical features in machine learning datasets. Understanding the different scaler techniques and their impact on various algorithms empowers data scientists to preprocess data effectively, leading to improved model performance.
