
This article delves into a specific preprocessing technique offered by Scikit-Learn: preprocessing.add_dummy_feature.
We will explore how this function enhances dataset compatibility, learn how to use it effectively, and illustrate its application through practical examples.
Whether you’re new to data preprocessing or seeking to expand your knowledge, this article provides valuable insights into harnessing the power of add_dummy_feature in your Python-based machine learning projects.
 add_dummy_features" class="wp-image-2033"/>
add_dummy_features" class="wp-image-2033"/>What is add_dummy_feature?
add_dummy_feature is a function in Scikit-Learn’s preprocessing module that adds a new feature with constant value to an existing dataset.
Why Use add_dummy_feature?
Adding a dummy feature is useful for algorithms that assume a certain dimensionality, enhancing compatibility.
How to Use add_dummy_feature?
Simply import it from Scikit-Learn’s preprocessing module and apply it to your dataset.
When to Add a Dummy Feature?
Add a dummy feature when your dataset requires a constant dimensionality for certain algorithms.
Does It Affect the Data?
Yes, it increases the dimensionality by one and adds a feature with a constant value.
Can It Impact Model Performance?
For some algorithms, a constant feature may hinder performance, so use it judiciously.
What Are Common Use Cases?
Commonly used when an algorithm expects a specific number of input features.
How Does It Benefit Algorithms?
It ensures consistent dimensionality across training and testing data, preventing errors.
What If the Added Feature Is Irrelevant?
Irrelevant features could lead to noise in the data, potentially affecting model accuracy.
Why Choose add_dummy_feature Over Manual Addition?
Scikit-Learn automates the process, making it more efficient and consistent.
Python code Examples
Adding Dummy Feature using Scikit-Learn
from sklearn.preprocessing import add_dummy_feature
import numpy as np
data = np.array([[1, 2], [3, 4], [5, 6]])
data_with_dummy = add_dummy_feature(data)
print("Original Data:")
print(data)
print("Data with Dummy Feature:")
print(data_with_dummy)

from sklearn.datasets import load_iris
from sklearn.preprocessing import add_dummy_feature
import matplotlib.pyplot as plt
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Add a dummy feature to the dataset
X_with_dummy = add_dummy_feature(X)
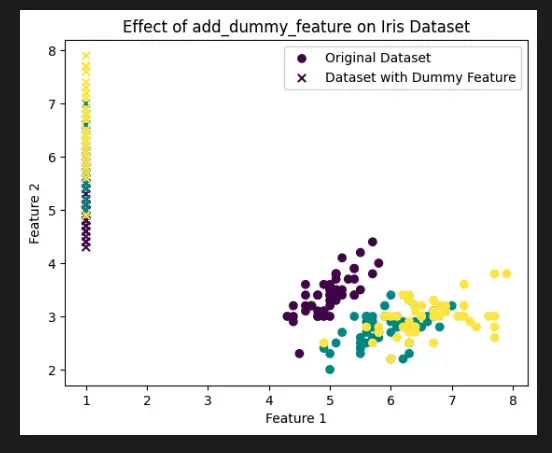
# Create scatter plots to visualize the first two features
plt.scatter(X[:, 0], X[:, 1], c=y, label='Original Dataset')
plt.scatter(X_with_dummy[:, 0], X_with_dummy[:, 1], c=y, marker='x', label='Dataset with Dummy Feature')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.title('Effect of add_dummy_feature on Iris Dataset')
plt.show()

Alternative to add_dummy_feature
An alternative to Scikit-Learn’s add_dummy_feature is the OneHotEncoder from the same library. While both methods deal with categorical variables, they have differences in terms of their application.
The add_dummy_feature function adds a new feature with a constant value to the dataset, which is useful for algorithms that expect a consistent dimensionality. On the other hand, the OneHotEncoder is specifically designed for converting categorical variables into binary vectors, each representing a unique category.
Here’s a Python code example illustrating the use of OneHotEncoder as an alternative to add_dummy_feature:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Sample categorical data
categorical_data = np.array([['A'], ['B'], ['C'], ['A'], ['B']])
# Initialize OneHotEncoder
encoder = OneHotEncoder()
# Fit and transform the categorical data
encoded_data = encoder.fit_transform(categorical_data).toarray()
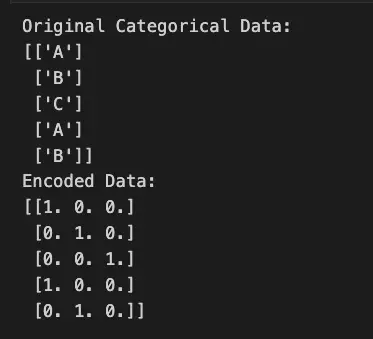
print("Original Categorical Data:")
print(categorical_data)
print("Encoded Data:")
print(encoded_data)
Relevant Entities
| Entity | Properties |
| add_dummy_feature | Function in Scikit-Learn preprocessing module |
| Dataset | Input data to which the dummy feature is added |
| Constant Value | The value of the dummy feature added |
| Algorithms | Some algorithms expect consistent dimensionality |
| Dimensionality | Number of features in the dataset |
| Model Performance | Impact of the added feature on algorithm performance |
Important Concepts in Scikit-Learn Preprocessing add_dummy_feature
- Data Preprocessing
- Feature Engineering
- Dimensionality
- Algorithm Compatibility
To Know Before You Learn Scikit-Learn Preprocessing add_dummy_feature?
- Basic understanding of data preprocessing in machine learning
- Familiarity with categorical variables and their representation
- Understanding of dimensionality and its significance in algorithms
- Basic knowledge of Scikit-Learn library and its utilities
What’s Next?
- Using Scikit-Learn’s OneHotEncoder for categorical variable encoding
- Exploring advanced data preprocessing techniques
- Understanding feature scaling and normalization
- Learning about handling missing data in datasets
Sources
- Scikit-Learn Documentation: The official documentation provides detailed information and examples about various preprocessing techniques, including add_dummy_feature. scikit-learn.org/stable/modules/preprocessing.html#adding-dummy-features">Scikit-Learn Preprocessing Documentation
- Stack Overflow: A popular platform where developers and data scientists discuss various coding challenges and techniques. You can find code snippets, explanations, and discussions related to add_dummy_feature.
- Towards Data Science: This platform hosts a wide range of articles and tutorials on machine learning topics. Look for articles specifically focused on Scikit-Learn Preprocessing and the use of add_dummy_feature.
- Kaggle: Kaggle is a community for data science enthusiasts. It offers datasets, competitions, and tutorials. You can find notebooks and discussions related to preprocessing techniques, including add_dummy_feature. Website:
- Machine Learning Mastery: This website provides practical tutorials and guides on various machine learning topics, including preprocessing techniques in Scikit-Learn.
