
Welcome to this article that delves into the realm of Scikit-Learn preprocessing encoders. Data preprocessing is a crucial step in machine learning, and encoders play a pivotal role in transforming categorical data into formats suitable for algorithms.
 encoders in Matplotlib" class="wp-image-2173"/>
encoders in Matplotlib" class="wp-image-2173"/>What Are Scikit-Learn Preprocessing Encoders?
Scikit-Learn preprocessing encoders are tools that convert categorical data into a numeric format, enabling machine learning models to process them effectively.
Why Use Encoders in Preprocessing?
Encoders resolve the challenge of incorporating categorical data into machine learning models, which typically require numerical input.
Types of Scikit-Learn Preprocessing Encoders
Scikit-Learn offers various encoders catering to different categorical data scenarios:
- LabelEncoder: Converts categorical labels into integers.
- OneHotEncoder: Creates binary columns for each category.
- OrdinalEncoder: Maps categories to ordinal numeric values.
When to Use Each Encoder?
Each encoder has its ideal use case:
- Use LabelEncoder for target variables in classification.
- Employ OneHotEncoder for nominal features without inherent order.
- Opt for OrdinalEncoder with ordinal data featuring a meaningful order.
How to Choose the Right Encoder?
Choosing the right encoder depends on the data type and the specific problem you’re addressing.
Encoding Strategies and Their Impact
The choice of encoding strategy can impact the performance of your machine learning models:
- Label Encoding: May introduce unintended ordinal relationships.
- One-Hot Encoding: Prevents bias due to category relationships.
- Ordinal Encoding: Preserves ordinal relationships, but may not suit nominal data.
Overview of Sklearn Encoders
Scikit-Learn provides three distinct encoders for handling categorical data: LabelEncoder, OneHotEncoder, and OrdinalEncoder.
LabelEncoderconverts categorical labels into sequential integer values, often used for encoding target variables in classification.OneHotEncodertransforms categorical features into a binary matrix, representing the presence or absence of each category. This prevents biases due to category relationships.OrdinalEncoderencodes ordinal categorical data by assigning numerical values based on order, maintaining relationships between categories. These encoders play vital roles in transforming diverse categorical data types into formats compatible with various machine learning algorithms.
| Encoder | Advantages | Disadvantages | Best Use Case |
|---|---|---|---|
| LabelEncoder | Simple and efficient encoding. Useful for target variables. Preserves natural order. | Doesn’t create additional features. Not suitable for features without order. | Classification tasks where labels have a meaningful order. |
| OneHotEncoder | Prevents bias due to category relationships. Useful for nominal categorical features. Compatible with various algorithms. | Creates high-dimensional data. Potential multicollinearity issues. | Machine learning algorithms requiring numeric input, especially for nominal data. |
| OrdinalEncoder | Maintains ordinal relationships. Handles meaningful order. Useful for features with inherent hierarchy. | May introduce unintended relationships. Not suitable for nominal data. | Features with clear ordinal rankings, like education levels or ratings. |
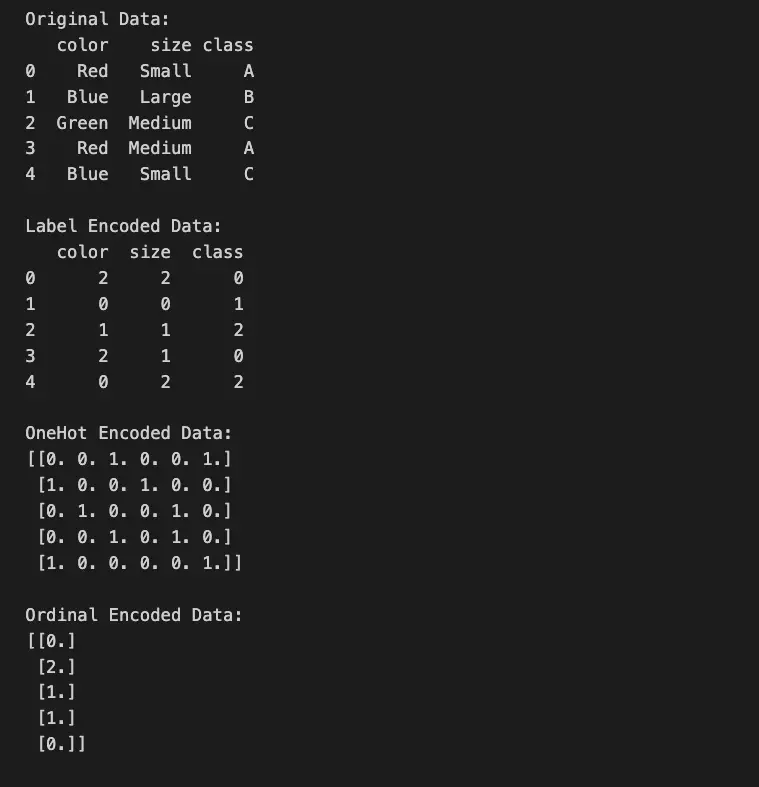
Python Examples
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, OrdinalEncoder
import pandas as pd
# Create a sample dataset
data = pd.DataFrame({
'color': ['Red', 'Blue', 'Green', 'Red', 'Blue'],
'size': ['Small', 'Large', 'Medium', 'Medium', 'Small'],
'class': ['A', 'B', 'C', 'A', 'C']
})
# Using LabelEncoder
label_encoder = LabelEncoder()
data_label_encoded = data.copy()
for column in data.columns:
data_label_encoded[column] = label_encoder.fit_transform(data[column])
# Using OneHotEncoder
onehot_encoder = OneHotEncoder()
data_onehot_encoded = onehot_encoder.fit_transform(data[['color', 'size']]).toarray()
# Using OrdinalEncoder
ordinal_encoder = OrdinalEncoder(categories=[['Small', 'Medium', 'Large']])
data_ordinal_encoded = ordinal_encoder.fit_transform(data[['size']])
print("Original Data:")
print(data)
print("\nLabel Encoded Data:")
print(data_label_encoded)
print("\nOneHot Encoded Data:")
print(data_onehot_encoded)
print("\nOrdinal Encoded Data:")
print(data_ordinal_encoded)
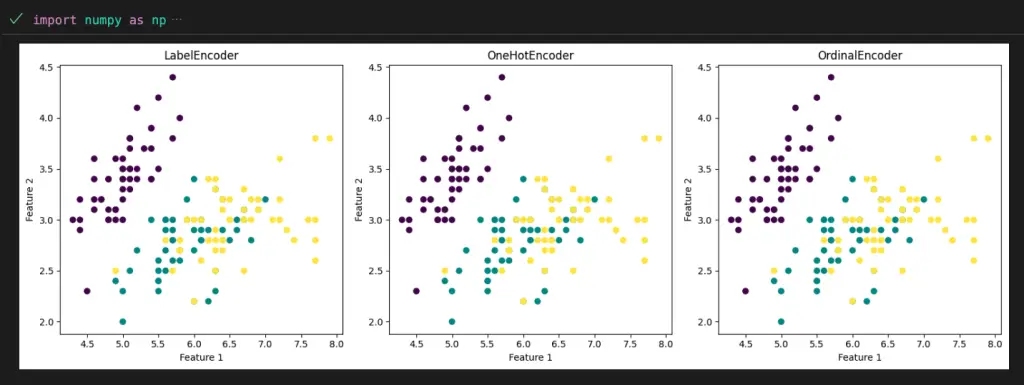
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, OrdinalEncoder
# Load the Iris dataset
iris = load_iris()
X = iris.data
species = iris.target_names[iris.target]
# Encode the species labels using different encoders
label_encoder = LabelEncoder()
label_encoded_species = label_encoder.fit_transform(species)
one_hot_encoder = OneHotEncoder()
one_hot_encoded_species = one_hot_encoder.fit_transform(species.reshape(-1, 1)).toarray()
ordinal_encoder = OrdinalEncoder()
ordinal_encoded_species = ordinal_encoder.fit_transform(species.reshape(-1, 1))
# Create subplots to compare the effects of different encoders
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Plot using LabelEncoder
axes[0].scatter(X[:, 0], X[:, 1], c=label_encoded_species)
axes[0].set_title("LabelEncoder")
axes[0].set_xlabel("Feature 1")
axes[0].set_ylabel("Feature 2")
# Plot using OneHotEncoder
axes[1].scatter(X[:, 0], X[:, 1], c=np.argmax(one_hot_encoded_species, axis=1))
axes[1].set_title("OneHotEncoder")
axes[1].set_xlabel("Feature 1")
axes[1].set_ylabel("Feature 2")
# Plot using OrdinalEncoder
axes[2].scatter(X[:, 0], X[:, 1], c=ordinal_encoded_species)
axes[2].set_title("OrdinalEncoder")
axes[2].set_xlabel("Feature 1")
axes[2].set_ylabel("Feature 2")
plt.tight_layout()
plt.show()
Important Concepts in Scikit-Learn Encoders
- Feature Encoding
- Categorical Data
- Nominal and Ordinal Categories
- Label Encoding
- One-Hot Encoding
- Ordinal Encoding
- Encoding Bias
- Feature Scaling
- Normalization
- Standardization
To Know Before You Learn Scikit-Learn Encoders?
- Understanding of Categorical Data
- Basic Python Programming Skills
- Familiarity with Scikit-Learn Library
- Knowledge of Data Preprocessing
- Concept of Feature Engineering
- Awareness of Machine Learning Algorithms
- Importance of Data Transformation
- Understanding of Feature Scaling
- Awareness of Encoding Techniques
- Experience with Data Analysis
What’s Next?
After learning about Scikit-Learn encoders, you’ll likely find these topics beneficial for enhancing your understanding of data preprocessing and machine learning:
- Feature Scaling Techniques
- Data Imputation and Cleaning
- Handling Imbalanced Data
- Feature Selection and Dimensionality Reduction
- Model Evaluation and Selection
- Hyperparameter Tuning
- Ensemble Learning Methods
- Deep Learning and Neural Networks
- Time Series Analysis and Forecasting
- Natural Language Processing (NLP)
Expanding your knowledge in these areas will contribute to your proficiency in machine learning and equip you to work on more complex and diverse projects.
Relevant Entities
| Entity | Properties |
|---|---|
| LabelEncoder | Converts categorical labels to integers. Used for target variables in classification. Preserves natural order of labels. |
| OneHotEncoder | Creates binary columns for each category. Prevents bias due to category relationships. Suitable for nominal categorical data. |
| OrdinalEncoder | Maps categories to ordinal numeric values. Preserves ordinal relationships. Useful for ordinal categorical data. |
| add_dummy_feature | Adds a dummy feature to the data. Useful for expanding feature space. Can help with linear regression and other algorithms. |
| fit | Method to compute required parameters. Used for fitting the encoder on training data. Generates parameters for data transformation. |
| transform | Method to apply encoding to new data. Used for transforming test or validation data. Applies the learned encoding to new samples. |
Conclusion
Scikit-Learn preprocessing encoders are indispensable tools for transforming categorical data into a format that machine learning algorithms can understand. Understanding the strengths and limitations of each encoder empowers data scientists to make informed choices in the preprocessing stage, ultimately leading to more accurate and effective models.
