
Scikit-Learn’s MultiLabelBinarizer is one of the Binarizers used in Scikit-learn for handling multilabel classification problems. It transforms multilabel datasets into binary matrices, making them compatible with various machine learning algorithms.
What is Multilabel Classification?
Multilabel classification is a classification task where each instance can be assigned multiple labels simultaneously. It’s common in applications like image classification, text categorization, and tagging systems.
How MultiLabelBinarizer Works
MultiLabelBinarizer transforms multilabel data into a binary matrix where each column represents a unique label, and each row corresponds to an instance. A value of 1 indicates the presence of a label, while 0 indicates its absence.
Benefits of Using MultiLabelBinarizer
- Efficiently handles multilabel data in a format suitable for various machine learning algorithms.
- Enables seamless integration of multilabel classification into existing Scikit-Learn pipelines.
- Helps manage complex labeling scenarios in real-world applications.
Use Cases for MultiLabelBinarizer
MultiLabelBinarizer is useful when dealing with:
- Image tagging, where an image can be associated with multiple descriptive tags.
- Document categorization, where a document may belong to several categories simultaneously.
- Social media analysis, where a post can be associated with multiple topics or sentiments.
Handling Imbalanced Multilabel Data
Imbalanced multilabel datasets can pose challenges. Techniques like class weighting and oversampling can be applied to mitigate imbalanced label distributions.
Considerations and Best Practices
- Ensure proper preprocessing of text or other input data before using MultiLabelBinarizer.
- Use relevant evaluation metrics for multilabel classification, such as hamming loss and Jaccard similarity.
- Choose appropriate algorithms that support multilabel outputs, like random forests and gradient boosting.
Python code Examples
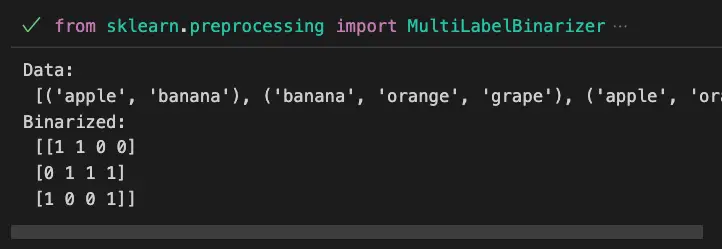
Example 1: Basic Usage
from sklearn.preprocessing import MultiLabelBinarizer
#Sample data
data = [('apple', 'banana'), ('banana', 'orange', 'grape'), ('apple', 'orange')]
#Create MultiLabelBinarizer instance
mlb = MultiLabelBinarizer()
#Transform data
binarized_data = mlb.fit_transform(data)
print('Data:\n',data)
print('Binarized:\n',binarized_data)
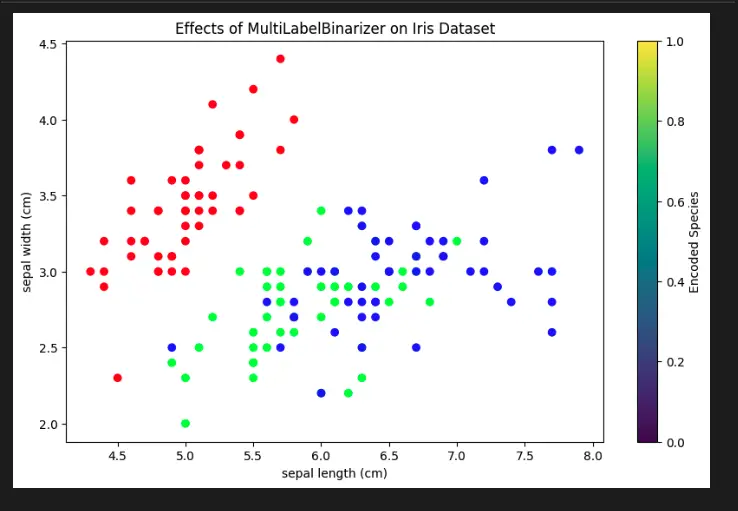
Visualize Scikit-Learn Preprocessing MultiLabelBinarizer with Python
To visualize the usage of Scikit-Learn’s MultiLabelBinarizer, we’ll create a simple plot using the Matplotlib library. In this example, we’ll use the built-in Iris dataset and apply the MultiLabelBinarizer to encode the species labels. Then, we’ll visualize the encoded labels using a scatter plot.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import MultiLabelBinarizer
# Load the Iris dataset
iris = load_iris()
species = iris.target_names[iris.target]
# Create MultiLabelBinarizer instance
mlb = MultiLabelBinarizer()
# Transform species labels
binarized_species = mlb.fit_transform([[s] for s in species])
# Create scatter plot
plt.figure(figsize=(10, 6))
plt.scatter(iris.data[:, 0], iris.data[:, 1], c=binarized_species)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title('Effects of MultiLabelBinarizer on Iris Dataset')
plt.colorbar(label='Encoded Species')
plt.show()
Relevant entities
| Entity | Properties |
|---|---|
| MultiLabelBinarizer | Transforms multilabel data into binary matrices for multilabel classification. |
| Multilabel Classification | Classification task where instances can have multiple labels simultaneously. |
| Binary Matrix | Matrix with binary values (0 and 1) indicating the presence or absence of labels. |
| Machine Learning Algorithms | Algorithms used to build models and make predictions on data. |
| Image Tagging | Process of associating multiple descriptive tags with an image. |
| Document Categorization | Assigning documents to multiple categories simultaneously. |
| Social Media Analysis | Studying social media posts to extract information and insights. |
| Class Weighting | Technique to assign different weights to classes based on their imbalance. |
| Oversampling | Creating additional instances of minority classes to balance dataset. |
| Hamming Loss | Evaluation metric for multilabel classification indicating label-wise accuracy. |
| Jaccard Similarity | Measures the similarity between two sets by comparing their intersection and union. |
| Random Forests | Ensemble learning method based on decision tree classifiers. |
| Gradient Boosting | Boosting algorithm that builds strong predictive models by combining weak learners. |
Important Concepts in Scikit-Learn Preprocessing MultiLabelBinarizer
- Data Preprocessing
- Multi-label Classification
- Binary Encoding
- Label Binarization
- One-Hot Encoding
To Know Before You Learn Scikit-Learn Preprocessing MultiLabelBinarizer
- Basics of Machine Learning
- Data Preprocessing Concepts
- Understanding Multi-label Classification
- Familiarity with Scikit-Learn Library
- Knowledge of Label Binarization Techniques
What’s Next?
- Advanced Labeling Techniques
- Handling Imbalanced Multi-label Data
- Feature Selection and Engineering
- Model Selection for Multi-label Classification
- Ensemble Techniques for Multi-label Classification
Conclusion
Scikit-Learn Preprocessing MultiLabelBinarizer is an indispensable tool for tackling multilabel classification tasks. By converting complex multilabel datasets into binary matrices, it enables the application of various machine learning techniques while preserving the integrity of multilabel relationships. With its flexibility and ease of integration, MultiLabelBinarizer empowers machine learning practitioners to address a wide range of real-world challenges.
