
If you’re new to the world of machine learning, you’ve probably heard the term “bag-of-words” thrown around. But what is it, and how can it help you in your ML projects? In this guide, we’ll dive into the basics of bag-of-words and show you how to use it to your advantage.
 bag of words matrix" class="wp-image-2342"/>
bag of words matrix" class="wp-image-2342"/>What is Bag-of-Words?
Bag-of-words is a technique used in natural language processing (NLP) to represent text data as a collection of words or tokens. It’s called “bag-of-words” because it essentially treats each document as a bag of its words, disregarding the order in which they appear.
Why Use Bag-of-Words in Machine Learning?
Bag-of-words is a popular technique in machine learning because it’s simple, efficient, and effective. By representing text data as a bag of its words, we can easily compute word frequencies, identify important keywords, and build models that can classify, cluster, or predict based on these features.
How to Use Bag-of-Words in Machine Learning
Bag-of-words can be used in a variety of ML tasks, such as sentiment analysis, topic modeling, and text classification. To use it, we need to first create a bag-of-words representation of our training data. Then, we can apply any ML algorithm that accepts vector inputs, such as Naive Bayes, Logistic Regression, or Support Vector Machines.
How to Create a Bag-of-Words Representation?
Creating a bag-of-words representation is straightforward. First, we need to tokenize our text data by splitting it into words or other meaningful units. Then, we create a vocabulary or a set of unique words that appear in our corpus. Finally, we represent each document as a vector of word counts, where each element corresponds to a word in our vocabulary.
Tips for Preprocessing Text Data
Preprocessing is crucial in NLP, especially when using bag-of-words. Some tips to keep in mind are to lowercase all text, remove stop words, punctuations, and special characters, and perform stemming or lemmatization to reduce the number of unique words.
Bags-of-Words VS Embeddings
Bag-of-words and word embeddings are two different techniques used for representing text data in machine learning. Here’s a comparison of the two approaches using Python:
Bag-of-words
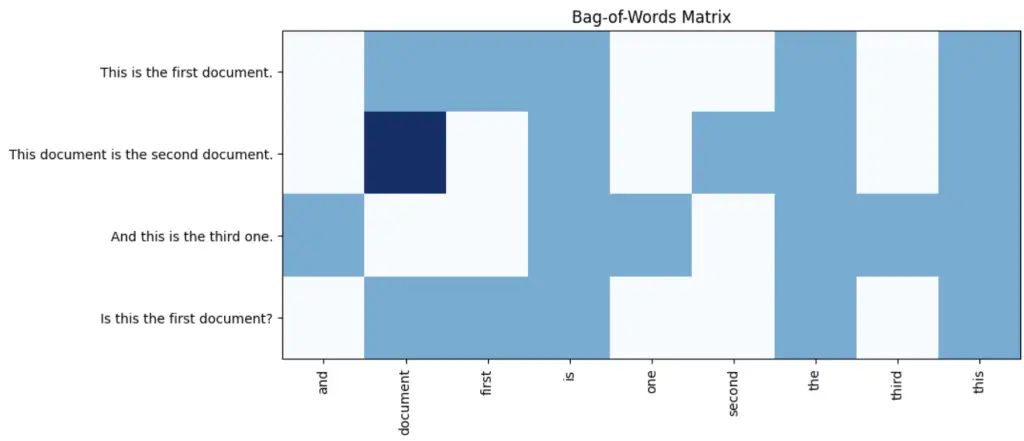
Bag-of-words represents text as a vector of word counts, where each word is treated as a separate feature. Here’s an example of visualizing a bag-of-words matrix using Matplotlib:
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.pyplot as plt
corpus = ['This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
fig, ax = plt.subplots(figsize=(10, 6))
ax.imshow(X.toarray(), cmap='Blues')
ax.set_xticks(range(len(vectorizer.get_feature_names_out())))
ax.set_xticklabels(vectorizer.get_feature_names_out(), rotation=90)
ax.set_yticks(range(len(corpus)))
ax.set_yticklabels(corpus)
ax.set_title('Bag-of-Words Matrix')
plt.show()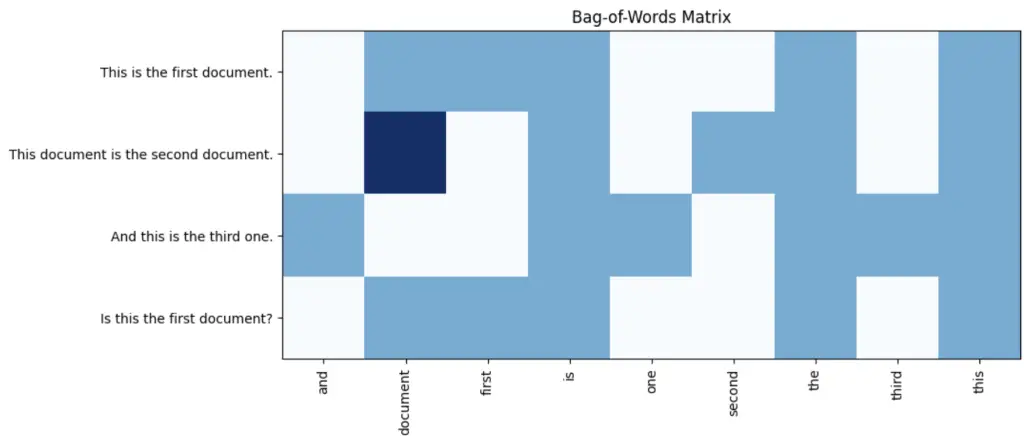
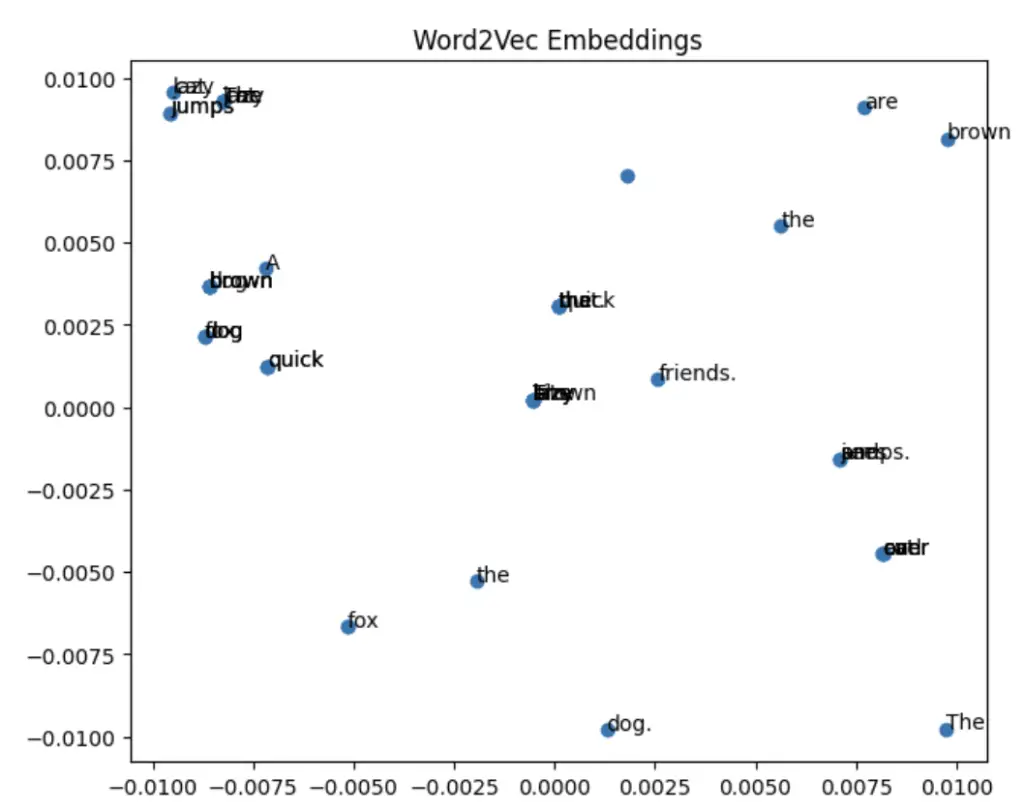
Embeddings (Word2Vec)
Word2Vec is a popular word embedding technique that represents words as vectors in a continuous vector space, where the distance between vectors reflects semantic similarity.
Here’s an example of visualizing word embeddings using Matplotlib:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from gensim.models import Word2Vec
# Define the corpus of sentences
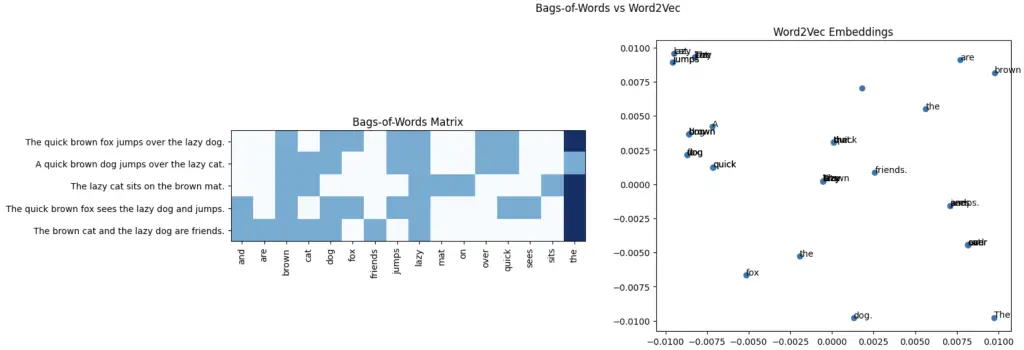
corpus = ['The quick brown fox jumps over the lazy dog.',
'A quick brown dog jumps over the lazy cat.',
'The lazy cat sits on the brown mat.',
'The quick brown fox sees the lazy dog and jumps.',
'The brown cat and the lazy dog are friends.']
# Bags-of-Words
vectorizer = CountVectorizer()
X_bow = vectorizer.fit_transform(corpus).toarray()
# Word2Vec
sentences = [sentence.split() for sentence in corpus]
model = Word2Vec(sentences, min_count=1)
X_w2v = np.array([model.wv[word] for sentence in sentences for word in sentence])
# Plot the results
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle('Bags-of-Words vs Word2Vec')
# Plot the Bags-of-Words matrix
ax1.imshow(X_bow, cmap='Blues')
ax1.set_xticks(np.arange(len(vectorizer.get_feature_names_out())))
ax1.set_xticklabels(vectorizer.get_feature_names_out(), rotation=90)
ax1.set_yticks(np.arange(len(corpus)))
ax1.set_yticklabels(corpus)
ax1.set_title('Bags-of-Words Matrix')
# Plot the Word2Vec embeddings
ax2.scatter(X_w2v[:, 0], X_w2v[:, 1])
for i, sentence in enumerate(sentences):
for j, word in enumerate(sentence):
ax2.annotate(word, (X_w2v[i*len(sentence)+j, 0], X_w2v[i*len(sentence)+j, 1]))
ax2.set_title('Word2Vec Embeddings')
plt.show()
In this code, we define a new corpus of sentences and apply the Bags-of-Words and Word2Vec techniques. We then plot both the Bags-of-Words matrix and the Word2Vec embeddings. The main difference between the two techniques is that Bags-of-Words represents each word as a one-hot encoded vector, while Word2Vec learns a continuous vector representation for each word based on its context in the corpus. This allows Word2Vec to capture more nuanced relationships between words, such as semantic and syntactic similarities.
 bag of words vs embeddings (word2vec)" class="wp-image-2344"/>
bag of words vs embeddings (word2vec)" class="wp-image-2344"/>Python Examples
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))
# Create the Bag-of-Words
vectorizer = CountVectorizer()
bow = vectorizer.fit_transform(newsgroups_train.data)
# Get the feature names (i.e., the unique words in the dataset)
feature_names = vectorizer.get_feature_names_out()
# Print the Bag-of-Words
print(bow)
In this example, we first load the fetch_20newsgroups dataset and remove the header, footer, and quotes from the text. Next, we create a CountVectorizer object, which will transform the text into a Bag-of-Words representation. We then use the fit_transform method of the CountVectorizer object to create the Bag-of-Words. Finally, we get the unique words in the dataset using the get_feature_names method of the CountVectorizer object and print the Bag-of-Words.
Pros of using bags-of-words in machine learning
- Simplicity: Bag-of-words is a simple and easy-to-understand representation of text data, making it accessible for beginners.
- Versatility: Bag-of-words can be used for a wide range of natural language processing (NLP) tasks, including text classification, sentiment analysis, and topic modeling.
- Efficiency: Bag-of-words can handle large datasets efficiently, and it can be scaled up to handle big data with distributed computing frameworks like Apache Spark.
- Interpretable Features: Bag-of-words provides interpretable features, making it easier to understand which words are important for a particular task.
Cons of using bags-of-words in machine learning
- Loss of Context: Bag-of-words treats each word as a separate feature and ignores the context in which the words appear, leading to a loss of information.
- High Dimensionality: Bag-of-words can result in a high-dimensional feature space, which can lead to overfitting and computational complexity.
- Sparsity: Bag-of-words can produce sparse matrices, where most of the entries are zero, which can lead to computational inefficiencies.
- No Semantic Information: Bag-of-words ignores the semantic relationships between words, resulting in a representation that does not capture the meaning of a text.
Datasets Useful for Bag-of-Words
20 Newsgroups
from sklearn.datasets import fetch_20newsgroups
#Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))
IMDB Movie Reviews
from nltk.corpus import movie_reviews
#Load the dataset
movie_reviews_data = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
Useful Python Libraries for Bag-of-Words
Here are some popular Python libraries and methods for implementing Bag-of-Words in machine learning:
scikit-learn: This library provides the CountVectorizer class which can be used to convert a collection of text documents to a matrix of token counts. The TfidfVectorizer class can also be used to convert a collection of text documents to a matrix of TF-IDF features.
NLTK: The Natural Language Toolkit (NLTK) is a library that provides many tools for working with human language data. The nltk.tokenize module can be used to tokenize text into individual words or sentences, while the nltk.probability module can be used to compute the frequency distribution of words.
gensim: This library is designed specifically for topic modeling and document similarity. The gensim.corpora.Dictionary class can be used to create a mapping between words and their integer ids, while the gensim.models.TfidfModel class can be used to transform a bag-of-words representation into a TF-IDF representation.
spaCy: This library is primarily designed for advanced natural language processing tasks, but it also provides a simple and efficient way to create bag-of-words representations. The nlp.tokenizer function can be used to tokenize text into individual words, while the nlp.vocab function can be used to create a vocabulary of unique words.
numpy: The NumPy library provides a range of mathematical functions and tools for working with arrays. It can be used to perform mathematical operations on bag-of-words matrices, such as computing the dot product between two matrices.
Important Concepts in Bag-of-Words
- Tokenization
- Stop Words
- Stemming and Lemmatization
- Count Vectorization
- TF-IDF Vectorization
- N-grams
- Sparse Matrix
- Document-Term Matrix
- Bag-of-Words Model
- Feature Extraction
- Text Classification
- Sentiment Analysis
- Topic Modeling
To Know Before You Learn Bag-of-Words
- Basic understanding of Machine Learning
- Knowledge of Text Preprocessing
- Familiarity with Natural Language Processing (NLP)
- Understanding of Document Classification
- Understanding of Feature Extraction Techniques
- Understanding of Vector Space Models
- Familiarity with Term Frequency-Inverse Document Frequency (TF-IDF) Model
- Understanding of Text Representation Techniques
- Understanding of Data Structures like Arrays, Matrices, and Vectors
- Basic knowledge of Python Programming Language
What’s Next?
- Word Embeddings (e.g., Word2Vec, GloVe)
- Recurrent Neural Networks (RNNs)
- Convolutional Neural Networks (CNNs)
- Deep Learning for Natural Language Processing (NLP)
- Topic Modeling Techniques (e.g., Latent Dirichlet Allocation (LDA))
- Sequence Models (e.g., Hidden Markov Models (HMMs))
- Named Entity Recognition (NER)
- Sentiment Analysis Techniques (e.g., VADER, TextBlob)
- Text Summarization Techniques
- Machine Translation Techniques
- Information Retrieval Techniques (e.g., Vector Space Model, Latent Semantic Indexing (LSI))
Alternatives to Bags-of-Words
Word Embeddings: Word embeddings represent words in a continuous vector space, where the distance between vectors reflects semantic similarity. Popular word embedding techniques include Word2Vec and GloVe.
Convolutional Neural Networks (CNNs): CNNs can directly learn useful features from raw text by treating them as images. This approach is called the character-level convolutional neural network.
Recurrent Neural Networks (RNNs): RNNs are designed to handle sequential data, and they can be used for modeling text data. Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) are popular RNN architectures for text modeling.
Transformer Models: Transformer models like BERT, GPT, and T5 have achieved state-of-the-art performance in various natural language processing tasks, including text classification, question-answering, and text generation.
Topic Models: Topic models like Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF) can discover the underlying topics in a collection of documents, which can be useful for document clustering and retrieval.
Graph-based Models: Graph-based models like Graph Convolutional Networks (GCNs) can represent text data as graphs and learn useful representations by leveraging graph structure.
Relevant Entities
| Entity | Properties |
|---|---|
| Bag-of-Words | A technique used in NLP to represent text data as a collection of words or tokens |
| Natural Language Processing (NLP) | A branch of AI that deals with the interaction between computers and humans’ natural languages |
| Tokenization | The process of breaking down text data into words or other meaningful units |
| Vocabulary | A set of unique words that appear in our corpus |
| Word Frequencies | The count of how many times each word appears in a document or corpus |
| Stop Words | Words that are common in a language but usually do not carry significant meaning in a specific context |
| Punctuations and Special Characters | Characters such as commas, periods, and symbols that may not be significant in a specific context and can be removed during preprocessing |
| Stemming and Lemmatization | Techniques used to reduce the number of unique words by grouping words with the same stem or lemma together |
| Machine Learning | A branch of AI that deals with algorithms and statistical models that allow computer systems to learn from data and make predictions or decisions |
| Naive Bayes, Logistic Regression, and Support Vector Machines | Common ML algorithms that can accept vector inputs and be used with bag-of-words representations |
Conclusion
In conclusion, bag-of-words is a simple yet powerful technique that can help you extract useful features from text data and build effective machine learning models. By following the steps outlined in this guide and experimenting with different preprocessing techniques and ML algorithms, you’ll be on your way to becoming a bag-of-words expert in no time!
Sources:
- Bag-of-Words Model – Wikipedia
- lemmatization-examples-python/">Lemmatization Examples in Python – Machine Learning Plus
