
Data preprocessing is a critical step in preparing datasets for machine learning models. Scikit-Learn’s preprocessing module offers a valuable tool known as quantile_transform that helps transform data into a specific distribution.
 quantile_transform() in Matplotlib" class="wp-image-2226"/>
quantile_transform() in Matplotlib" class="wp-image-2226"/>Understanding Quantile Transformation
Quantile transformation is a technique that maps data to a specified distribution by transforming it based on the quantiles of the desired distribution. This process can help to achieve a more uniform or Gaussian-like distribution.
The Role of quantile_transform
The quantile_transform function in Scikit-Learn’s preprocessing module enables you to apply quantile transformation to your data. It’s particularly useful when you want to mitigate the impact of outliers or ensure a uniform distribution.
Key Features and Parameters
- n_quantiles: Specifies the number of quantiles used for mapping.
- output_distribution: Determines the desired output distribution.
- ignore_implicit_zeros: Controls whether to ignore implicit zero values.
Benefits of Using quantile_transform
- Outlier Handling: quantile_transform can mitigate the effects of outliers on your data.
- Desired Distribution: You can achieve a specific desired distribution for your data.
- Uniformization: It can help make your data more uniformly distributed.
Using quantile_transform in Your Workflow
- Import the necessary module: Import quantile_transform from sklearn.preprocessing.
- Prepare your data: Ensure your data is cleaned and ready for transformation.
- Instantiate and transform: Create an instance of quantile_transform and apply it to your data.
- Further processing: Use the transformed data for your machine learning tasks.
Considerations and Caveats
- Data Distribution: Ensure that the quantile transformation aligns with your data’s characteristics.
- Interpretation: Transformed data might not be as intuitive to interpret as the original data.
- Parameter Tuning: Adjust parameters to achieve the desired transformation effect.
Python Code Examples
quantile_transform Example
import numpy as np
from sklearn.preprocessing import quantile_transform
# Sample data with positive skewness
data = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
# Apply quantile transformation
transformed_data = quantile_transform(data, n_quantiles=5, output_distribution='uniform')
print(f'Data:\n {data}\n')
print(f'Transformed Data:\n {transformed_data}\n')

Visualize Scikit-Learn Preprocessing quantile_transform with Python
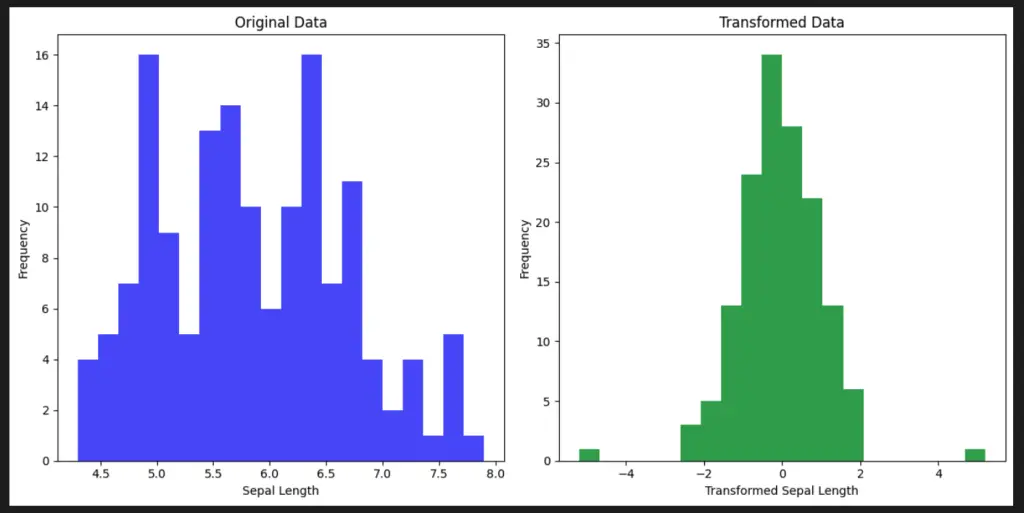
To gain a better understanding of the effects of the quantile_transform function from Scikit-Learn’s preprocessing module, we can visualize its impact on a built-in dataset using the Matplotlib library.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import quantile_transform
# Load the Iris dataset
data = load_iris()
X = data.data[:, 0].reshape(-1, 1) # Select sepal length feature
# Apply quantile transformation
transformed_data = quantile_transform(X, n_quantiles=10, output_distribution='normal')
# Create subplots
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Plot original data
axes[0].hist(X, bins=20, color='blue', alpha=0.7)
axes[0].set_title('Original Data')
axes[0].set_xlabel('Sepal Length')
axes[0].set_ylabel('Frequency')
# Plot transformed data
axes[1].hist(transformed_data, bins=20, color='green', alpha=0.7)
axes[1].set_title('Transformed Data')
axes[1].set_xlabel('Transformed Sepal Length')
axes[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
In this code example, we use the Iris dataset and focus on the sepal length feature. We apply the quantile_transform function with 10 quantiles and a normal distribution as the desired output. The code then creates a side-by-side comparison of the original and transformed data distributions using histograms.
quantile_transform() in Matplotlib" class="wp-image-2226" style="width:830px;height:416px" width="830" height="416"/>This visualization helps us observe how quantile transformation alters the data distribution and its potential impact on machine learning models.
Important Concepts in Scikit-Learn Preprocessing quantile_transform
- Data Transformation
- Quantiles and Percentiles
- Desired Output Distribution
- Outliers and Their Impact
- Data Skewness
- Uniform and Gaussian Distributions
- Machine Learning Preprocessing
- Quantile Transformation Parameters
To Know Before You Learn Scikit-Learn Preprocessing quantile_transform?
- Basic understanding of machine learning concepts and terminology.
- Familiarity with Python programming language and its syntax.
- Knowledge of data preprocessing techniques like scaling and encoding.
- Understanding of data distributions, percentiles, and quantiles.
- Awareness of the impact of outliers on data analysis and modeling.
- Familiarity with the Scikit-Learn library and its preprocessing module.
- Basic grasp of statistical concepts such as mean, median, and variance.
- Awareness of different types of data transformations and their purposes.
What’s Next?
- Data Standardization: Exploring techniques to scale features to a standard range.
- Handling Outliers: Learning about methods to identify and manage outliers in data.
- Feature Engineering: Exploring ways to create new features for model improvement.
- Advanced Preprocessing: Delving into more complex data preprocessing techniques.
- Model Selection: Understanding how to choose appropriate algorithms for transformed data.
- Hyperparameter Tuning: Optimizing model performance through parameter adjustments.
- Model Evaluation: Learning about metrics to assess model effectiveness.
- Ensemble Methods: Exploring techniques to combine multiple models for predictions.
Relevant Entities
| Entities | Properties |
|---|---|
| quantile_transform | Scikit-Learn function for data transformation |
| Data Distribution | Pattern of data values across a range |
| Quantiles | Values dividing data into equal portions |
| Output Distribution | Desired distribution after transformation |
| Outliers | Extreme values affecting data analysis |
| Uniform Distribution | Even spread of data values |
| Data Preprocessing | Enhancing data for machine learning |
Sources
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.quantile_transform.html">Scikit-Learn Documentation: The official documentation provides detailed information about the quantile_transform function.
- Machine Learning Mastery: This resource offers insights into applying quantile_transform in various scenarios.
Conclusion
Scikit-Learn’s quantile_transform offers a powerful method to manipulate data distributions, improving their suitability for machine learning algorithms. By understanding how to utilize this function effectively, you can enhance your preprocessing pipeline and potentially enhance the performance of your models.
