
Welcome to this article where we delve into the powerful world of machine learning preprocessing using Scikit-Learn’s OneHotEncoder. Preprocessing is a crucial step in any machine learning pipeline. The OneHotEncoder is one of the Scikit-Learn Encoders used for handling categorical data effectively.
Understanding Categorical Data
Categorical data consists of non-numeric values that represent categories or labels, such as color, gender, or country. Machine learning algorithms often require numerical data, making preprocessing crucial.
The Role of OneHotEncoder
The OneHotEncoder is designed to convert categorical variables into a binary matrix, where each column represents a unique category and each row indicates the presence or absence of that category.
Handling Categorical Variables
OneHotEncoder tackles the challenge of encoding categorical variables by creating binary columns for each category, effectively representing the categorical information in a way that machine learning algorithms can process.
Working Principle
OneHotEncoder takes a categorical feature and encodes it into multiple binary features, with each binary feature corresponding to a specific category.
Use Cases
- Text classification tasks
- Recommendation systems
- Categorical data in regression problems
Benefits of OneHotEncoder
- Preserves the categorical information without imposing order
- Enables machine learning models to process categorical data
- Minimizes bias by removing numerical relationships between categories
Challenges and Considerations
OneHotEncoding can lead to high-dimensional data, especially when dealing with large categorical features, which might impact computational efficiency.
Applying OneHotEncoder
OneHotEncoder is typically used in combination with other preprocessing techniques and machine learning algorithms, ensuring that categorical data is appropriately transformed and fed into the model.
Python Code Examples
Example 1: Using Scikit-Learn Preprocessing OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
import numpy as np
data = np.array([['Red'],
['Blue'],
['Green'],
['Red']])
encoder = OneHotEncoder()
encoded_data = encoder.fit_transform(data).toarray()
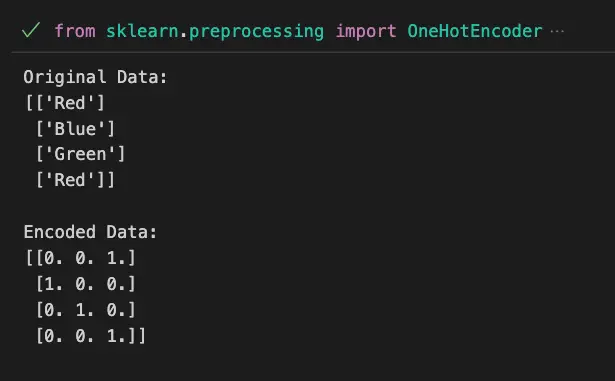
print("Original Data:")
print(data)
print("\nEncoded Data:")
print(encoded_data)
Visualize Scikit-Learn Preprocessing OneHotEncoder with Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import OneHotEncoder
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Apply OneHotEncoder
encoder = OneHotEncoder()
y_encoded = encoder.fit_transform(y.reshape(-1, 1)).toarray()
# Plot the original and encoded data
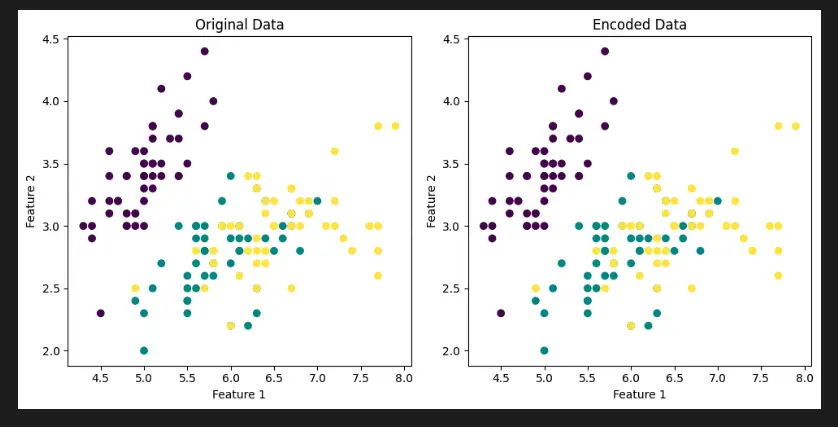
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title('Original Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.subplot(1, 2, 2)
plt.scatter(X[:, 0], X[:, 1], c=np.argmax(y_encoded, axis=1))
plt.title('Encoded Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.tight_layout()
plt.show()
This code uses the Matplotlib library to visualize the effect of the Scikit-Learn Preprocessing OneHotEncoder on the Iris dataset. It loads the Iris dataset, applies the OneHotEncoder to encode the target variable, and then creates a side-by-side comparison of the original and encoded data.
Sklearn Encoders
Scikit-Learn provides three distinct encoders for handling categorical data: LabelEncoder, OneHotEncoder, and OrdinalEncoder.
LabelEncoderconverts categorical labels into sequential integer values, often used for encoding target variables in classification.OneHotEncodertransforms categorical features into a binary matrix, representing the presence or absence of each category. This prevents biases due to category relationships.OrdinalEncoderencodes ordinal categorical data by assigning numerical values based on order, maintaining relationships between categories. These encoders play vital roles in transforming diverse categorical data types into formats compatible with various machine learning algorithms.
| Encoder | Advantages | Disadvantages | Best Use Case |
|---|---|---|---|
| LabelEncoder | Simple and efficient encoding. Useful for target variables. Preserves natural order. | Doesn’t create additional features. Not suitable for features without order. | Classification tasks where labels have a meaningful order. |
| OneHotEncoder | Prevents bias due to category relationships. Useful for nominal categorical features. Compatible with various algorithms. | Creates high-dimensional data. Potential multicollinearity issues. | Machine learning algorithms requiring numeric input, especially for nominal data. |
| OrdinalEncoder | Maintains ordinal relationships. Handles meaningful order. Useful for features with inherent hierarchy. | May introduce unintended relationships. Not suitable for nominal data. | Features with clear ordinal rankings, like education levels or ratings. |
Python Example
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, OrdinalEncoder
import pandas as pd
# Create a sample dataset
data = pd.DataFrame({
'color': ['Red', 'Blue', 'Green', 'Red', 'Blue'],
'size': ['Small', 'Large', 'Medium', 'Medium', 'Small'],
'class': ['A', 'B', 'C', 'A', 'C']
})
# Using LabelEncoder
label_encoder = LabelEncoder()
data_label_encoded = data.copy()
for column in data.columns:
data_label_encoded[column] = label_encoder.fit_transform(data[column])
# Using OneHotEncoder
onehot_encoder = OneHotEncoder()
data_onehot_encoded = onehot_encoder.fit_transform(data[['color', 'size']]).toarray()
# Using OrdinalEncoder
ordinal_encoder = OrdinalEncoder(categories=[['Small', 'Medium', 'Large']])
data_ordinal_encoded = ordinal_encoder.fit_transform(data[['size']])
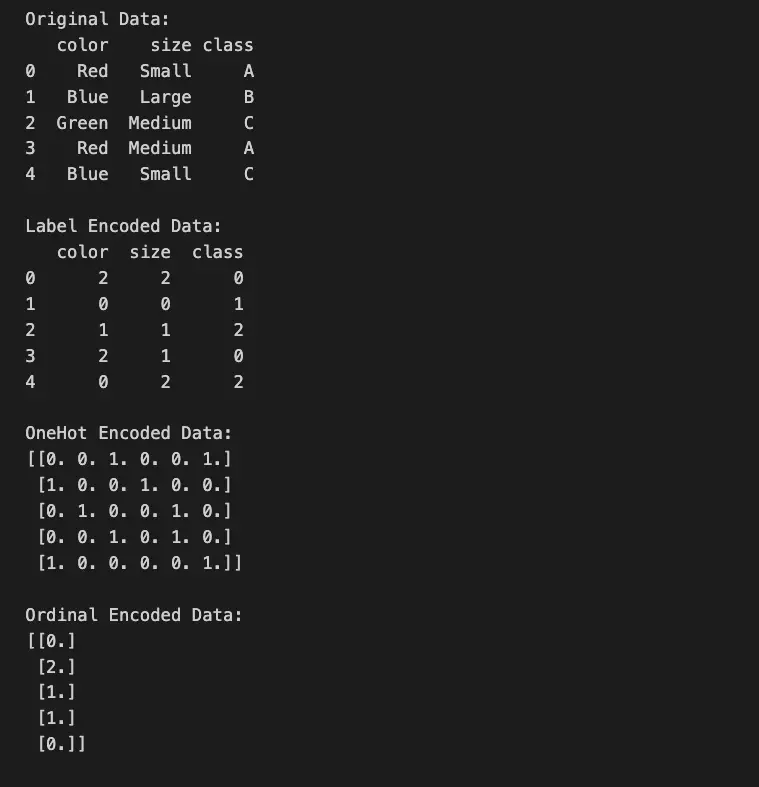
print("Original Data:")
print(data)
print("\nLabel Encoded Data:")
print(data_label_encoded)
print("\nOneHot Encoded Data:")
print(data_onehot_encoded)
print("\nOrdinal Encoded Data:")
print(data_ordinal_encoded)
To learn more, read our blog post on Scikit-learn encoders.
To Know Before You Learn Scikit-Learn Preprocessing OneHotEncoder?
- Understanding of categorical data and its significance in machine learning
- Familiarity with basic data preprocessing techniques
- Knowledge of feature engineering and variable encoding
- Awareness of how different machine learning algorithms handle categorical data
- Fundamentals of using Scikit-Learn library for machine learning tasks
Important Concepts in Scikit-Learn Preprocessing OneHotEncoder
- Categorical data and its challenges
- Encoding techniques for categorical variables
- Binary matrix representation
- Handling high-dimensional data
- Interpreting OneHotEncoded features
What’s Next?
- Introduction to handling missing data in machine learning
- Exploration of advanced feature engineering techniques
- Understanding other encoding methods (Label Encoding, Target Encoding)
- Integration of preprocessing techniques into a machine learning pipeline
- Application of OneHotEncoder in real-world projects
- Investigation of categorical data visualization and interpretation
Relevant Entities
| Entities | Properties |
|---|---|
| Scikit-Learn OneHotEncoder | Converts categorical variables into binary matrices for machine learning. |
| Categorical Data | Non-numeric values representing categories, e.g., color, gender. |
| Categorical Variables | Features with non-numeric values needing encoding for ML algorithms. |
| Binary Matrix | Matrix with binary columns representing presence or absence of categories. |
| Text Classification | Task of categorizing text data into predefined classes. |
| Recommendation Systems | Algorithms suggesting items based on user preferences. |
Sources
Here are some of the most popular pages for learning about Scikit-Learn Preprocessing OneHotEncoder in machine learning:
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html" target="_blank" rel="noreferrer noopener">Scikit-Learn Documentation on OneHotEncoder
- Handling Categorical Data in Python
- A Comprehensive Guide to Encoding Categorical Features
- Using Categorical Data with One-Hot Encoding
- A Comprehensive Guide to Different Types of Categorical Data Encoding
These resources provide in-depth insights into Scikit-Learn Preprocessing OneHotEncoder and its application in machine learning scenarios.
Conclusion
The Scikit-Learn OneHotEncoder is a crucial tool in the machine learning toolbox for preprocessing categorical data. It enables data scientists and practitioners to effectively handle and encode categorical variables, contributing to the success of various machine learning tasks.
