
Welcome to this article where we delve into the world of machine learning preprocessing using Scikit-Learn’s Normalizer. Preprocessing is a crucial step in any machine learning pipeline, and the Normalizer offered by Scikit-Learn is a powerful tool that deserves your attention.
Understanding Preprocessing
Preprocessing involves transforming raw data into a format that is more suitable for machine learning algorithms. It aims to improve the quality of the data, making it easier for models to extract meaningful patterns.
The Role of the Normalizer
The Normalizer in Scikit-Learn focuses on transforming individual samples to have unit norm. It’s particularly useful when the scale of features varies widely.
Feature Scaling vs. Normalization
Feature scaling adjusts the range of features while normalization adjusts the values so they fall within a certain range. Normalization ensures that samples have a consistent scale.
Working Principle
The Normalizer works on each sample independently. It calculates the norm of each sample and then scales the individual features by dividing them by the computed norm.
Types of Norms
- L1 Norm: Also known as the Manhattan norm, it’s the sum of absolute values.
- L2 Norm: Also known as the Euclidean norm, it’s the square root of the sum of squared values.
- Max Norm: Scales each feature by the maximum absolute value in the sample.
Use Cases
The Normalizer is beneficial when dealing with text classification, clustering, and recommendation systems.
Benefits of Normalization
- Avoids issues caused by varying scales of features.
- Improves the efficiency of gradient-based optimization algorithms.
- Enhances the model’s ability to find patterns in the data.
Applying the Normalizer
Applying the Normalizer in Scikit-Learn is straightforward. It’s usually used in combination with other preprocessing techniques and machine learning algorithms.
Python Code Examples
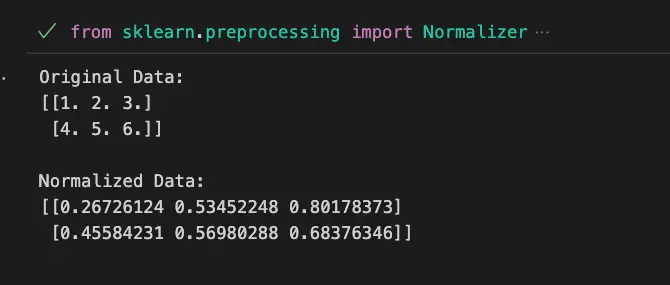
Example 1: Using Scikit-Learn Preprocessing Normalizer
from sklearn.preprocessing import Normalizer
import numpy as np
data = np.array([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]])
normalizer = Normalizer(norm='l2')
normalized_data = normalizer.transform(data)
print("Original Data:")
print(data)
print("\nNormalized Data:")
print(normalized_data)
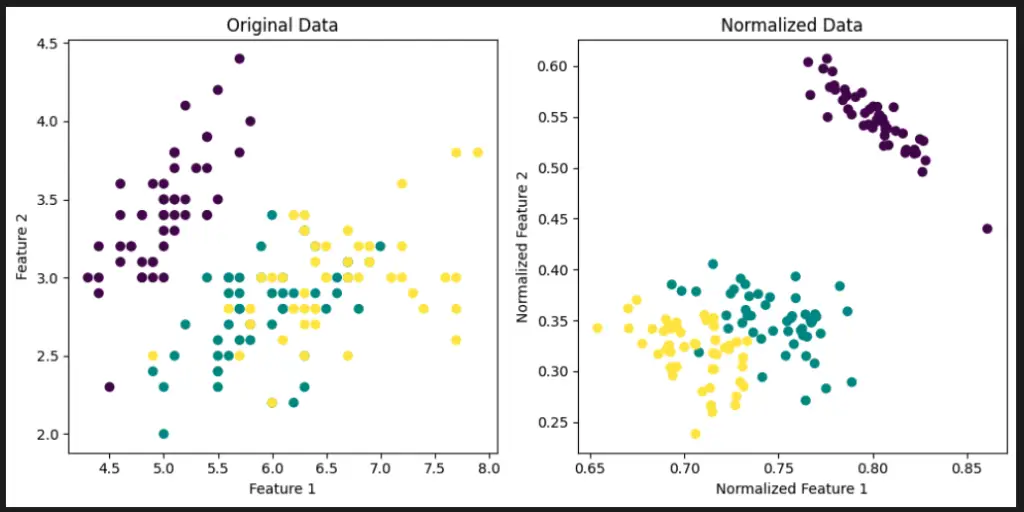
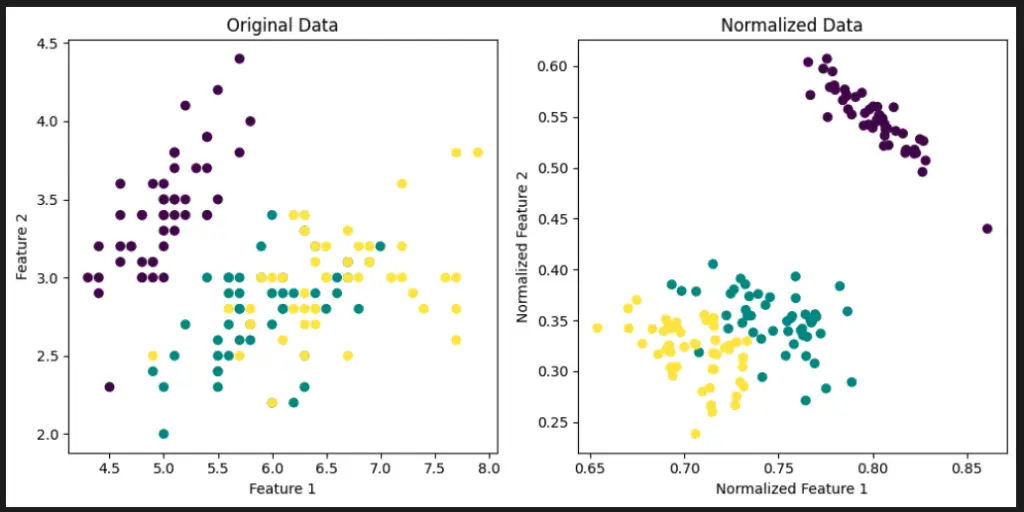
Visualize Scikit-Learn Preprocessing Normalizer with Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import Normalizer
# Load the Iris dataset
iris = load_iris()
X = iris.data
# Apply the Normalizer
normalizer = Normalizer(norm='l2')
X_normalized = normalizer.transform(X)
# Plot original and normalized data
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=iris.target)
plt.title('Original Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.subplot(1, 2, 2)
plt.scatter(X_normalized[:, 0], X_normalized[:, 1], c=iris.target)
plt.title('Normalized Data')
plt.xlabel('Normalized Feature 1')
plt.ylabel('Normalized Feature 2')
plt.tight_layout()
plt.show()
This code uses the Matplotlib library to visualize the effect of the Scikit-Learn Preprocessing Normalizer on the Iris dataset. It loads the Iris dataset, applies the Normalizer to normalize the features, and then creates a side-by-side comparison of the original and normalized data.
Important Concepts in Scikit-Learn Preprocessing Normalizer
- Feature Scaling
- Normalization Techniques
- L1 and L2 Norms
- Preprocessing in Machine Learning
- Dimensionality Reduction
- Effect on Model Performance
To Know Before You Learn Scikit-Learn Preprocessing Normalizer?
- Basic understanding of machine learning principles
- Familiarity with Scikit-Learn library
- Concept of feature scaling and normalization
- Understanding of different norm types (L1, L2, Max)
- Knowledge of how data preprocessing affects model performance
- Experience working with datasets and feature engineering
What’s Next?
- Introduction to other Scikit-Learn preprocessing techniques
- Exploration of different feature selection methods
- Deep dive into dimensionality reduction algorithms
- Advanced topics in regularization and model optimization
- Application of preprocessing in specific machine learning tasks
- Hands-on projects to reinforce preprocessing concepts
Relevant Entities
| Entities | Properties |
|---|---|
| Scikit-Learn Normalizer | Preprocessing tool for scaling individual samples’ features to unit norm. |
| Preprocessing | Transforming raw data into a suitable format for machine learning algorithms. |
| Feature Scaling | Adjusting feature ranges to prevent issues caused by varying scales. |
| Normalization | Scaling values so they fall within a specified range for consistency. |
| L1 Norm | Sum of absolute values, used for feature scaling. |
| L2 Norm | Euclidean norm, square root of sum of squared values, used for scaling. |
| Max Norm | Scaling features by the maximum absolute value in a sample. |
Sources
Here are some of the most popular pages for learning about Scikit-Learn Preprocessing Normalizer in machine learning:
- scikit-learn.org/stable/modules/preprocessing.html#normalization" target="_blank" rel="noreferrer noopener">Scikit-Learn Documentation on Normalization
- scikit-learn-a-complete-and-comprehensive-guide-670cb98fcfb9" target="_blank" rel="noreferrer noopener">Preprocessing with Scikit-Learn: A Complete Guide
These resources provide a comprehensive understanding of Scikit-Learn Preprocessing Normalizer and its application in machine learning.
Conclusion
The Scikit-Learn Normalizer is a valuable tool for ensuring that your data is appropriately scaled and normalized, leading to improved machine learning model performance. Understanding how to use it effectively can contribute to the success of your projects.