
In the realm of machine learning, data preprocessing plays a vital role in preparing data for accurate model training and predictions. One powerful tool offered by Scikit-Learn is the PowerTransformer class, which assists in transforming and normalizing data distributions.
Understanding Power Transformation
Power transformation is a technique used to modify the distribution of data, making it adhere more closely to a Gaussian (normal) distribution. This transformation can help stabilize variance, reduce skewness, and meet assumptions of some machine learning algorithms.
The Role of PowerTransformer
The PowerTransformer class in Scikit-Learn’s preprocessing module provides an effective way to apply power transformations to your data. It supports both the Yeo-Johnson and Box-Cox methods for transformation.
Benefits of Using PowerTransformer
- Handles skewness: PowerTransformer is particularly useful for data with skewness towards one tail.
- Enhances model compatibility: Many machine learning algorithms assume normal distribution, and power transformation helps meet this assumption.
- Reduces outlier effects: Power transformation mitigates the impact of extreme values on analysis.
Working with PowerTransformer
Using the PowerTransformer class involves a few straightforward steps:
- Import the necessary module: Import PowerTransformer from sklearn.preprocessing.
- Prepare your data: Ensure your data is ready for transformation.
- Instantiate PowerTransformer: Create an instance of PowerTransformer with your chosen method.
- Fit and transform: Fit the transformer to your data and then transform it.
Parameters of PowerTransformer
The PowerTransformer class offers parameters for customization:
- method: Choose ‘yeo-johnson’ or ‘box-cox’ transformation.
- standardize: If True, standardize the transformed data to have zero mean and unit variance.
When to Use PowerTransformer
PowerTransformer is particularly useful when dealing with data distributions that are skewed or non-Gaussian. It can be beneficial when you observe that your data’s distribution doesn’t meet the assumptions of the chosen machine learning algorithm.
Python Code Examples
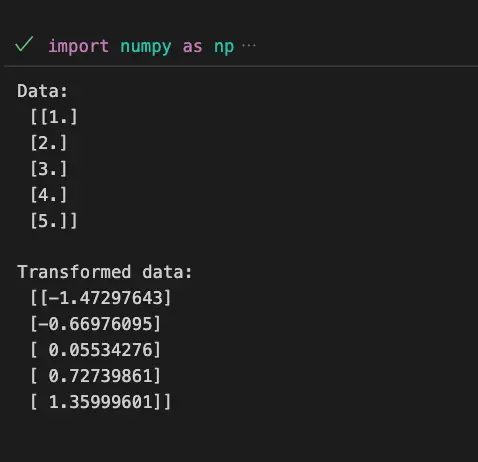
PowerTransformer Example
import numpy as np
from sklearn.preprocessing import PowerTransformer
# Sample data with positive skewness
data = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]])
# Instantiate PowerTransformer with Yeo-Johnson method
transformer = PowerTransformer(method='yeo-johnson')
# Fit and transform the data
transformed_data = transformer.fit_transform(data)
print(transformed_data)
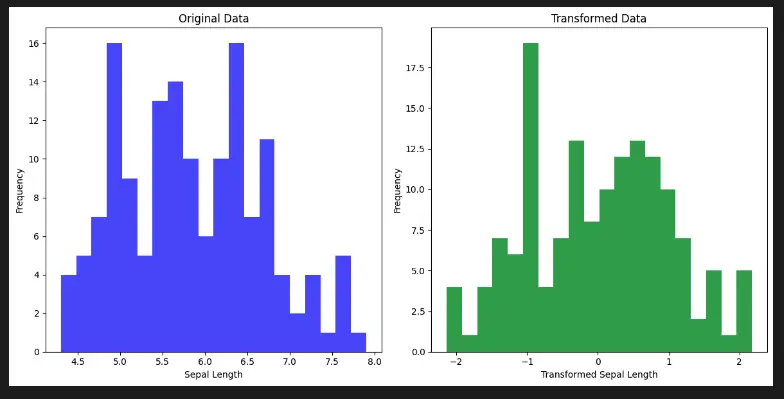
Visualize Scikit-Learn Preprocessing PowerTransformer with Python
Visualizing the effects of PowerTransformer from Scikit-Learn’s preprocessing module can provide insights into its impact on data distributions. This can be achieved using the Matplotlib library and a built-in dataset.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import PowerTransformer
# Load the Iris dataset
data = load_iris()
X = data.data[:, 0].reshape(-1, 1) # Select sepal length feature
# Instantiate PowerTransformer with Yeo-Johnson method
transformer = PowerTransformer(method='yeo-johnson')
# Fit and transform the data
transformed_data = transformer.fit_transform(X)
# Create subplots
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Plot original data
axes[0].hist(X, bins=20, color='blue', alpha=0.7)
axes[0].set_title('Original Data')
axes[0].set_xlabel('Sepal Length')
axes[0].set_ylabel('Frequency')
# Plot transformed data
axes[1].hist(transformed_data, bins=20, color='green', alpha=0.7)
axes[1].set_title('Transformed Data')
axes[1].set_xlabel('Transformed Sepal Length')
axes[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
In this code example, we use the Iris dataset and focus on the sepal length feature. We apply the Yeo-Johnson power transformation using the PowerTransformer class. The code then creates a side-by-side comparison of the original and transformed data distributions using histograms.
This visualization helps us understand how the power transformation affects the distribution of the data and its potential impact on machine learning models.
Important Concepts in Scikit-Learn Preprocessing PowerTransformer
- Power Transformation
- Normalization of Data Distributions
- Yeo-Johnson and Box-Cox Methods
- Data Skewness and Symmetry
- Machine Learning Assumptions
- Impact on Model Performance
- Standardization of Transformed Data
- Data Preprocessing Techniques
To Know Before You Learn Scikit-Learn Preprocessing PowerTransformer?
- Basic understanding of machine learning principles and algorithms.
- Familiarity with Python programming and its libraries.
- Knowledge of data preprocessing techniques like scaling and encoding.
- Understanding of data distributions and their properties.
- Awareness of skewness and its impact on data analysis.
- Basic grasp of statistical concepts like mean, median, and variance.
- Understanding of the assumptions underlying machine learning algorithms.
- Familiarity with Scikit-Learn library and its modules.
What’s Next?
- Feature Engineering: Creating new features from existing ones to improve model performance.
- Handling Outliers: Techniques to identify and manage outliers in your dataset.
- Advanced Preprocessing: Exploring other techniques for data transformation and cleaning.
- Model Selection: Choosing appropriate machine learning algorithms for your transformed data.
- Hyperparameter Tuning: Optimizing model performance through parameter adjustments.
- Ensemble Methods: Learning about combining multiple models for better predictions.
- Validation and Testing: Understanding how to assess model performance accurately.
- Deployment: Taking your trained model and making it available for predictions.
Relevant Entities
| Entities | Properties |
|---|---|
| PowerTransformer | Scikit-Learn class for power transformations |
| Power Transformation | Technique to modify data distribution |
| Yeo-Johnson | Method for power transformation |
| Box-Cox | Alternative method for power transformation |
| Skewness | Measure of data distribution asymmetry |
| Gaussian Distribution | Normal distribution with symmetry |
| Machine Learning Assumptions | Expectations algorithms have about data distribution |
Sources
- scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PowerTransformer.html">Scikit-Learn Documentation: The official documentation provides in-depth information about the PowerTransformer class and its usage.
Conclusion
Scikit-Learn’s PowerTransformer offers a powerful way to transform data distributions, making them more suitable for machine learning tasks. By applying power transformations, you can enhance model performance, meet algorithm assumptions, and improve the robustness of your analyses.
