
Data preprocessing is a crucial step in machine learning that involves transforming raw data into a suitable format for training models. One effective way to streamline and organize this process is by using data preprocessing pipelines. In this article, we’ll explore the concept of data preprocessing pipelines, their benefits, and how to implement them in your machine learning workflows.
What are Data Preprocessing Pipelines?
A data preprocessing pipeline is a series of sequential data transformation steps that are applied to the raw input data to prepare it for model training and evaluation. These pipelines help maintain consistency, ensure reproducibility, and enhance the efficiency of the preprocessing process.
Source: Wikipedia article on Data Preprocessing
Benefits of Using Data Preprocessing Pipelines
- Organized Workflow: Pipelines allow you to structure your preprocessing steps in a clear and systematic manner.
- Reproducibility: Pipelines ensure that the same preprocessing steps are applied consistently to different datasets.
- Ease of Maintenance: Changes to preprocessing steps can be made in one place, reducing the risk of errors.
- Time Efficiency: Pipelines automate the preprocessing process, saving time and effort.
Implementing Data Preprocessing Pipelines
To implement data preprocessing pipelines in your machine learning projects, you can use libraries such as Scikit-Learn and TensorFlow. These libraries provide tools and classes for creating and executing pipelines.
Scikit-Learn’s Pipeline class allows you to chain together preprocessing steps and a final estimator into a single object. This object can then be used for fitting and predicting with the entire pipeline.
Key Steps in a Data Preprocessing Pipeline
- Data Cleaning: Handling missing values, outliers, and noisy data.
- Feature Scaling: Standardizing or normalizing features to bring them to a similar scale.
- Feature Transformation: Applying transformations like log transformations or polynomial features.
- Encoding Categorical Data: Converting categorical variables into numerical representations.
- Feature Selection: Selecting the most relevant features for modeling.
Example: Building a Data Preprocessing Pipeline
Here’s a simplified example of how to build a data preprocessing pipeline using Scikit-Learn:
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
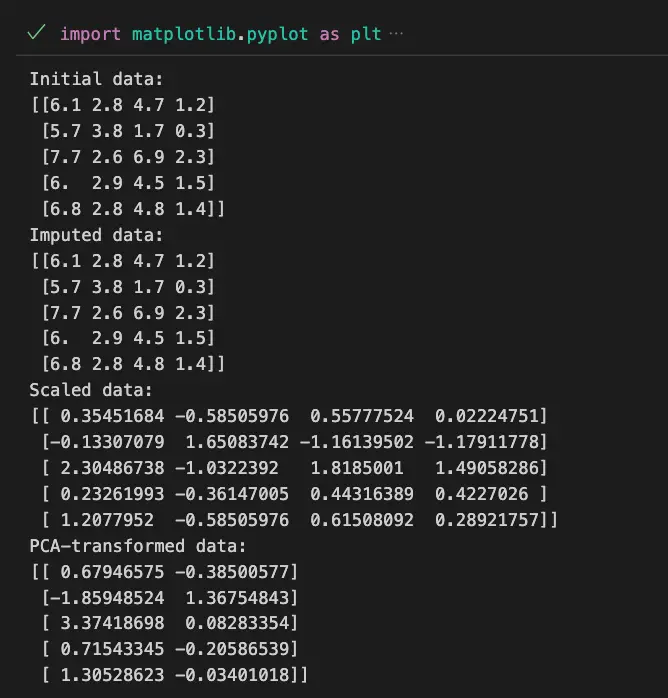
# Display the initial data
print("Initial data:")
print(X_test[:5])
# Create a pipeline
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('pca', PCA(n_components=2)),
('model', LogisticRegression())
])
# Fit and predict using the pipeline
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
# Transform and print results of preprocessing steps
X_imputed = pipeline.named_steps['imputer'].transform(X_test)
X_scaled = pipeline.named_steps['scaler'].transform(X_imputed)
X_pca = pipeline.named_steps['pca'].transform(X_scaled)
print("Imputed data:")
print(X_imputed[:5])
print("Scaled data:")
print(X_scaled[:5])
print("PCA-transformed data:")
print(X_pca[:5])
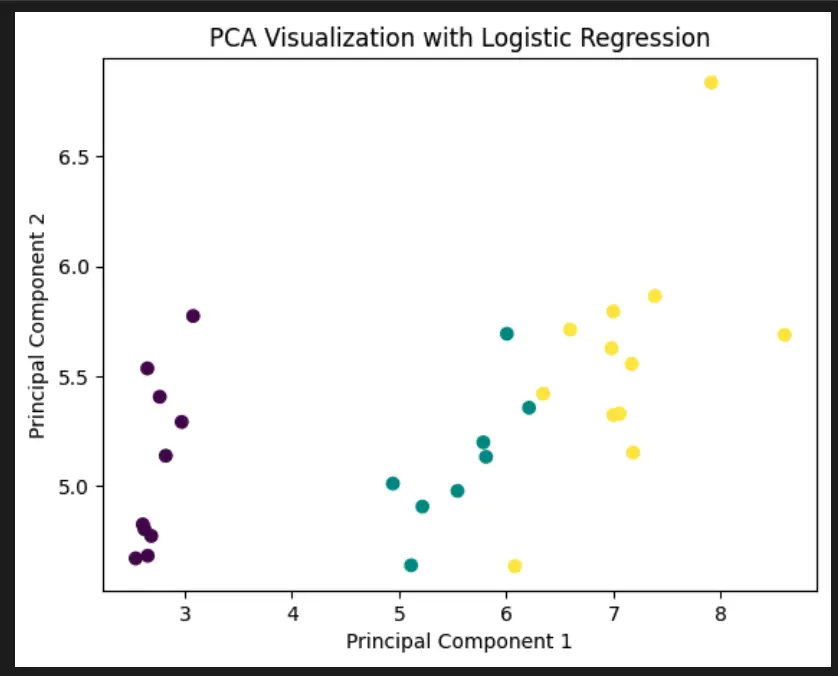
# Visualize the first two principal components
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_pred, cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA Visualization with Logistic Regression')
plt.show()In this code, you can see how each of the preprocessing tool in the pipeline impacted the data.
Here the imputer changed nothing since there was no missing data. The scaler scaled the data on the variance and the PCA performed dimensionality reduction.
Then, the plot made with matplotlib shows the end result.
The preprocessing pipeline used in the example above demonstrates a typical data preprocessing and machine learning workflow. Here’s an explanation of each step in the pipeline:
- Data Loading and Splitting:
- The example begins by loading the Iris dataset using
load_iris()fromsklearn.datasets. - The dataset is then split into training and testing sets using
train_test_split()fromsklearn.model_selection.
- The example begins by loading the Iris dataset using
- Pipeline Creation:
- A
Pipelineobject is created to encapsulate the preprocessing and modeling steps. - Each step is defined as a tuple containing a name (string) and an associated transformer or estimator object.
- The pipeline will ensure that each step is executed sequentially during fitting and prediction.
- A
- Imputation (SimpleImputer):
- The first step in the pipeline is to handle missing data using
SimpleImputer. - The strategy chosen is
'mean', which replaces missing values with the mean of the non-missing values in the corresponding feature.
- The first step in the pipeline is to handle missing data using
- Feature Scaling (StandardScaler):
- The next step is feature scaling using
StandardScaler. - This step standardizes the feature values by subtracting the mean and dividing by the standard deviation.
- Standardizing features ensures that each feature contributes equally to the modeling process.
- The next step is feature scaling using
- Dimensionality Reduction (PCA):
- The third step is dimensionality reduction using
PCA(Principal Component Analysis). - PCA reduces the number of features while preserving the most important information.
- In this example, PCA is configured to reduce the data to 2 principal components.
- The third step is dimensionality reduction using
- Model Training (LogisticRegression):
- The final step in the pipeline is training a logistic regression model using
LogisticRegression. - Logistic regression is a simple linear model used for binary and multi-class classification tasks.
- The model is trained on the processed data to learn the relationships between the features and target classes.
- The final step in the pipeline is training a logistic regression model using
- Fitting and Prediction:
- The pipeline is fitted to the training data using
fit(). - Once the pipeline is trained, it can be used to predict the target values on the test data using
predict().
- The pipeline is fitted to the training data using
- Visualization:
- After prediction, the first two principal components obtained from the PCA step are extracted.
- These components are used to create a scatter plot where each point is colored according to the predicted class.
- This visualization helps to understand how well the logistic regression model separates the classes in the reduced-dimensional space.
In summary, the pipeline combines various preprocessing steps (imputation, scaling, and dimensionality reduction) with a machine learning model (logistic regression) into a cohesive workflow. This allows for efficient and consistent data processing, model training, and prediction, while also facilitating interpretability and visualization of the results.
For more examples check out the Scikit-Learn Pipeline Example on Stackoverflow
Relevant Entities
| Entity | Properties |
|---|---|
| Pipeline | Sequential collection of data preprocessing and modeling steps. |
| SimpleImputer | Handles missing data by imputing missing values based on a specified strategy. |
| StandardScaler | Standardizes features by removing the mean and scaling to unit variance. |
| PCA (Principal Component Analysis) | Performs dimensionality reduction by projecting data onto principal components. |
| LogisticRegression | Estimates the relationship between input features and a binary or multiclass target. |
| train_test_split | Splits a dataset into training and testing subsets for model evaluation. |
Conclusion
Data preprocessing pipelines offer a systematic and efficient approach to preparing your data for machine learning tasks. By organizing preprocessing steps and incorporating them into pipelines, you can improve reproducibility, save time, and build more reliable and accurate models.
Whether you’re dealing with structured or unstructured data, mastering the art of data preprocessing pipelines is an essential skill for any machine learning practitioner.
