
NLP with Spacy: Unleashing the Power of Natural Language Processing
Natural Language Processing (NLP) has become one of the most exciting fields in machine learning today. With the help of advanced tools like Spacy, it’s now possible to analyze, understand, and manipulate human language in ways that were previously thought impossible.
In this article, we’ll explore the world of NLP with Spacy, one of the most popular and powerful NLP libraries available today. We’ll dive into the basics of Spacy, its features, and how you can use it to solve real-world problems.


The Basics of Spacy
Spacy is an open-source library designed for advanced natural language processing. It’s written in Python and is widely used by researchers, developers, and businesses around the world.
According to Spacy’s website, the library is designed to help you “build intelligent language applications that are optimized for performance, accuracy, and scale.” With Spacy, you can perform a wide range of NLP tasks, including entity recognition, part-of-speech tagging, text classification, and more.
One of the most significant advantages of Spacy is its speed. Spacy is built from the ground up with performance in mind, which means that it’s much faster than many other NLP libraries. This speed makes it an excellent choice for applications that require real-time processing, such as chatbots, voice assistants, and social media monitoring tools.
How to Use Spacy
Getting started with Spacy is relatively straightforward. First, you’ll need to install the library using pip. Once you have Spacy installed, you can start using its various features to analyze and manipulate text.
Spacy’s API is designed to be simple and easy to use, making it a great choice for developers of all skill levels. You can use Spacy to perform a wide range of NLP tasks, from simple text analysis to complex machine learning algorithms.
One of the best ways to get started with Spacy is to explore its documentation and examples. The Spacy website provides comprehensive documentation that covers all of the library’s features in detail. You can also find a wide range of examples and tutorials online that demonstrate how to use Spacy to solve real-world problems.
Install spaCy with Python
To install Spacy with Python, you can follow these steps:
Open your command prompt or terminal
Enter the following command:
pip install spacyPress Enter to execute the command
Wait for the installation to complete
After installation, you can verify the installation by importing Spacy in Python and printing its version. Here is an example:
import spacy
print(spacy.__version__)
This should print the version of Spacy installed in your system.
3.5.0The Features of Spacy
Spacy comes packed with features that make it one of the most powerful NLP libraries available. Here are some of the key features you’ll find in Spacy:
- Tokenization
- Lemmatization
- Part-of-speech tagging
- Named Entity Recognition
- Word Embeddings
- Information Extraction
- Dependency parsing
- Text Classification
Tokenization with SpaCy
Spacy tokenization breaks up text into individual words, phrases, or sentences.
import spacy
# Load Spacy's English language model
nlp = spacy.load('en_core_web_sm')
# Define the input text
text = "I love to play football. What about you?"
# Tokenize the input text using Spacy
doc = nlp(text)
# Print each token in the input text
for token in doc:
print(token.text)
# Visualize the tokenization using Spacy's built-in visualization tool
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True)
This code will tokenize the input text “I love to play football. What about you?” using Spacy and print each token in the input text.
I
love
to
play
football
.
What
about
you
?It will also visualize the tokenization using Spacy’s built-in visualization tool, which displays a dependency parse tree.
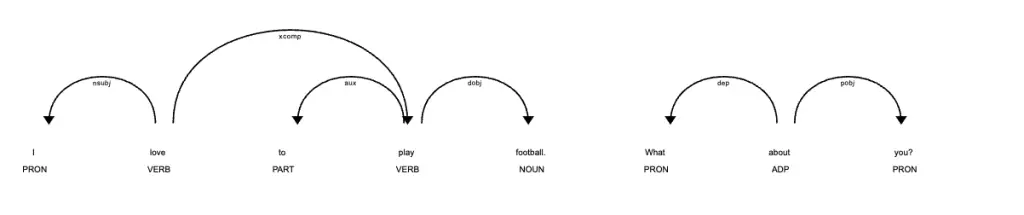
Understand the Dependency Parse Tree
In Spacy, the dependency parse tree is a tree-like structure that represents the grammatical structure of a sentence. It shows how words in a sentence are related to each other syntactically, and how they contribute to the overall meaning of the sentence.

Each node in the dependency parse tree represents a word in the sentence, and each edge represents the grammatical relationship between the words. The root node represents the main subject or predicate of the sentence, and each child node represents a modifier or argument of the root node.
The dependency parse tree can be used to extract useful information from text, such as identifying the subject and object of a sentence, or identifying the relationships between different parts of a sentence. It is also commonly used in natural language processing tasks such as named entity recognition, sentiment analysis, and text classification.
Lemmatization in SpaCy
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("The striped bats are hanging on their feet for best")
# Lemmatize each token in the text
lemmatized_text = " ".join([token.lemma_ for token in doc])
# Print the original text and the lemmatized text
print("Original Text: ", doc.text)
print("Lemmatized Text: ", lemmatized_text)
In the above code, we first load the English language model using spacy.load(). Then we create a Doc object by passing our text to the language model. Finally, we iterate over each token in the Doc object and get its lemmatized form using the lemma_ attribute. We then join all the lemmatized tokens to get the final lemmatized text.
Original Text: The striped bats are hanging on their feet for best
Lemmatized Text: the stripe bat be hang on their foot for goodPart-of-speech tagging with SpaCy
Part-of-speech tagging in Spacy helps identify the parts of speech (e.g., noun, verb, adjective) of each word in a sentence.
import spacy
from spacy import displacy
# Load the pre-trained English language model
nlp = spacy.load("en_core_web_sm")
# Define the input text to be tagged
text = "I am learning natural language processing with Spacy"
# Apply part-of-speech tagging to the input text
doc = nlp(text)
# Print the part-of-speech tags for each word in the input text
for token in doc:
print(token.text, token.pos_)
# Visualize the part-of-speech tags using displacy
displacy.render(doc, style="dep", jupyter=True)
This code loads the pre-trained English language model provided by Spacy, which includes a part-of-speech tagger.
It then defines an input text to be tagged, applies part-of-speech tagging to the text using the nlp object, and prints the part-of-speech tags for each word in the input text.
I PRON
am AUX
learning VERB
natural ADJ
language NOUN
processing NOUN
with ADP
Spacy PROPNIf you don’t know what these POS tags mean, read our article on spaCy POS tags.
Finally, it uses the displacy module to visualize the part-of-speech tags in a dependency tree format.

We can also learn more about the attributes of the POS tags by creating a pandas dataframe:
import pandas as pd
import spacy
# Load the English NLP model
nlp = spacy.load("en_core_web_sm")
# Define the input text to be tagged
text = "I am learning natural language processing with Spacy"
# Apply part-of-speech tagging to the input text
doc = nlp(text)
# Create a list to hold the POS tags
pos_tags = []
# Iterate over each token in the document
for token in doc:
# Append a dictionary with the POS tag information to the list
pos_tags.append({
"text": token.text,
"lemma": token.lemma_,
"pos": token.pos_,
"dep": token.dep_,
"is_punctuation": token.is_punct,
"is_alpha": token.is_alpha,
"is_stop": token.is_stop
# Add other attributes as needed
})
# Convert the list of POS tags to a pandas dataframe
df = pd.DataFrame(pos_tags)
# Print the resulting dataframe
df
Named entity recognition with SpaCy
Named entity recognition in Spacy helps identify and classify named entities (e.g., people, organizations, locations) in a sentence.
import spacy
nlp = spacy.load("en_core_web_sm")
# Sample text
text = "Apple is looking at buying U.K. startup for $1 billion"
# Parse the text with spacy
doc = nlp(text)
# Extract named entities
for entity in doc.ents:
print(entity.text, entity.label_)
In the above code, we first load the small English model of spacy using spacy.load(). Then, we define a sample text to perform NER on.
Next, we use nlp() to process the text and create a Doc object. Finally, we iterate over the entities recognized in the text using the ents attribute of the Doc object and print the text and label of each entity.
Apple ORG
U.K. GPE
$1 billion MONEYYou can visualize NER in spaCy using displacy.
import spacy
from spacy import displacy
# Load the default English NLP model
nlp = spacy.load('en_core_web_sm')
# Define the input text to be analyzed
text = "Google LLC is an American multinational technology company focusing on online advertising, search engine technology, cloud computing, computer software, quantum computing, e-commerce, artificial intelligence, and consumer electronics. Its parent company Alphabet is considered one of the Big Five American information technology companies, alongside Amazon, Apple, Meta, and Microsoft."
# Apply NER to the input text
doc = nlp(text)
# Visualize the NER result using displacy.render
displacy.render(doc, style='ent', jupyter=True)
Here’s an HTML table of the default entities understood by spaCy in named entity recognition:
| Entity | Description |
|---|---|
| PERSON | People, including fictional. |
| NORP | Nationalities or religious or political groups. |
| FAC | Buildings, airports, highways, bridges, etc. |
| ORG | Companies, agencies, institutions, etc. |
| GPE | Countries, cities, states. |
| LOC | Non-GPE locations, mountain ranges, bodies of water. |
| PRODUCT | Objects, vehicles, foods, etc. (Not services.) |
| EVENT | Named hurricanes, battles, wars, sports events, etc. |
| WORK_OF_ART | Titles of books, songs, etc. |
| LAW | Named documents made into laws. |
| LANGUAGE | Any named language. |
| DATE | Absolute or relative dates or periods. |
| TIME | Times smaller than a day. |
| PERCENT | Percentage, including “%”. |
| MONEY | Monetary values, including unit. |
| QUANTITY | Measurements, as of weight or distance. |
| ORDINAL | “first”, “second”, etc. |
| CARDINAL | Numerals that do not fall under another type. |
Word Embeddings in SpaCy
To perform word embeddings with spaCy, you will need to install “en_core_web_md”:
python3 -m spacy download en_core_web_md
import spacy
# load the spacy model
nlp = spacy.load("en_core_web_md")
# define your text
text = "apple banana orange"
# create a spacy doc object
doc = nlp(text)
# print the word embeddings for each token in the text
for token in doc:
print(token.text, token.vector)
This will output the word embeddings for each token in the text:

To display the word vectors on a graph you can:
# get the word vectors
vecs = [token.vector for token in doc]
# reduce the dimensionality of the vectors to 2D using PCA
pca = PCA(n_components=2)
vecs_2d = pca.fit_transform(vecs)
# plot the word embeddings in a 2D space
fig, ax = plt.subplots()
ax.scatter(vecs_2d[:,0], vecs_2d[:,1])
for i, txt in enumerate(doc):
ax.annotate(txt.text, (vecs_2d[i,0], vecs_2d[i,1]))
plt.show()
The chart is created using the spaCy library, which generates word embeddings (i.e., numerical representations) of words based on their meaning and context. Each word in the text is represented as a vector in a high-dimensional space, and the PCA algorithm is used to reduce the dimensionality of the vectors to 2D for visualization purposes.
The resulting chart shows the position of each word in the 2D space. Words that are semantically similar are expected to be closer to each other in the chart, as they have similar vector representations. For example, “apple” and “banana” are relatively close to each other, while “orange” is positioned further away.
The chart also displays the words themselves as labels, with each word positioned at the corresponding point in the 2D space. This allows for easy interpretation of the spatial relationships between the words.
Information Extraction with SpaCy
This code will extract named entities from the given text and print them along with their corresponding entity labels.
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Steve Jobs was the CEO of Apple Corp."
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
The output will be:
Steve Jobs PERSON
Apple Corp. ORGHere, en_core_web_sm is the small English language model provided by spacy. We load this model using spacy.load() function. Then we pass the text to this model and get the parsed document using nlp() function. We can access the named entities in the document using doc.ents attribute, which returns a tuple of (entity_text, entity_label) for each named entity in the document.
Dependency parsing in SpaCy
Dependency parsing in Spacy allows to check the grammatical structure of a sentence and identify relationships between words.
import spacy
# Load the small English model
nlp = spacy.load("en_core_web_sm")
# Define the text to be parsed
text = "John likes pizza with anchovies"
# Parse the text with spacy
doc = nlp(text)
# Print the dependency tree
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_,
[child for child in token.children])
# Visualize the dependency tree
from spacy import displacy
displacy.render(doc, style="dep")
This code uses the en_core_web_sm model from spacy to perform dependency parsing on the given text.
It prints out the dependency tree.
John nsubj likes VERB []
likes ROOT likes VERB [John, pizza, with]
pizza dobj likes VERB []
with prep likes VERB [anchovies]
anchovies pobj with ADP []Then, it visualizes it using displacy.render() method from spacy. The dependency tree shows how each word in the text is related to the other words based on their syntactic dependencies.
Text Classification in SpaCy
Text classification in Spacy is used to classify text into pre-defined categories (e.g., sentiment analysis).
import spacy
from spacy import displacy
from spacy.lang.en import English
from spacy.util import minibatch, compounding
# Load the English NLP model
nlp = spacy.load("en_core_web_sm")
# Define the categories for classification
categories = ["Politics", "Sports", "Entertainment"]
# Define the training data
train_data = [
("The President delivered a speech today on tax policy.", {"cats": {"Politics": 1, "Sports": 0, "Entertainment": 0}}),
("The Lakers won the game against the Warriors last night.", {"cats": {"Politics": 0, "Sports": 1, "Entertainment": 0}}),
("The new movie is getting great reviews from critics.", {"cats": {"Politics": 0, "Sports": 0, "Entertainment": 1}}),
# Add more training data here
]
# Define the number of training iterations
n_iter = 10
# Create a new pipeline for text classification
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe("textcat")
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
# Add the categories to the text classification pipeline
for category in categories:
textcat.add_label(category)
# Train the model
nlp.begin_training()
for i in range(n_iter):
losses = {}
batches = minibatch(train_data, size=compounding(4.0, 32.0, 1.001))
for batch in batches:
texts, annotations = zip(*batch)
nlp.update(texts, annotations, losses=losses)
print(f"Iteration {i}: Losses - {losses}")
# Test the model
test_data = [
"The Prime Minister met with the President to discuss foreign policy.",
"The Red Sox won the game against the Yankees last night.",
"The new album from the popular band is coming out next week."
# Add more test data here
]
for text in test_data:
doc = nlp(text)
print(f"Text: {text}")
for category in textcat.labels:
print(f"{category}: {doc.cats[category]}")
print("\n")
# Visualize the pipeline
displacy.serve(nlp("The President delivered a speech today on tax policy."))
In this example, we first load the English NLP model using spacy.load(). We then define the categories for classification and the training data, which consists of text examples labeled with the corresponding categories. We also define the number of training iterations to use.
We then create a new pipeline for text classification using nlp.create_pipe(), and add the categories to the pipeline using textcat.add_label(). We then train the model using the training data and the nlp.update() method.
After training the model, we test it using some test data and print out the predicted category for each example using the doc.cats property. Finally, we visualize the pipeline using displacy.serve().
Contextual disambiguation in spaCy
Contextual disambiguation is the process of resolving ambiguities in a given text by using contextual clues. This process is essential for understanding the meaning of a sentence and is used in various natural language processing tasks such as machine translation and information retrieval.
import spacy
from spacy import displacy
# Load the small English model
nlp = spacy.load("en_core_web_sm")
# Define a text to analyze
text = "I saw a man with a telescope."
# Parse the text with the model
doc = nlp(text)
# Visualize the entity recognizer output
displacy.render(doc, style="ent", jupyter=True)
# Define a list of possible labels for the entity "man"
labels = ["PERSON", "ORG", "GPE"]
# Loop over the entities in the document
for ent in doc.ents:
# Check if the entity label is "man"
if ent.label_ == "PERSON" and ent.text == "man":
# Get the token index of the entity in the document
token_index = ent.start
# Get the surrounding context of the entity
context = doc[max(0, token_index-3):min(len(doc), token_index+4)]
# Print the surrounding context and ask for input to disambiguate the entity
print(f"Context: {context.text}")
label = input(f"Please choose a label for the entity '{ent.text}': {labels}\n")
# Set the entity label to the user's choice
ent.label_ = label
# Visualize the updated entity recognizer output
displacy.render(doc, style="ent", jupyter=True)
This code first loads the small English model from SpaCy, then defines a text to analyze. The displacy.render() function is used to visualize the entity recognizer output, which initially only recognizes the entity “man” as a person.
The code then defines a list of possible labels for the entity “man”, and loops over the entities in the document to check if the entity label is “man”. If so, the code extracts the surrounding context of the entity and prompts the user to choose a label for the entity from the list of possible labels.
The entity label is then updated to the user’s choice, and the updated entity recognizer output is visualized using displacy.render(). This allows the user to disambiguate the named entity based on the surrounding context.
NLP Python Tutorials
- NLP with Gensim
- NLP with NLTK
- NLP with spaCy
- NLP with TextBlob
- NLP with Scikit-learn
NLTK VS spaCy VS Gensim
NLP with Gensim
Pros
- Focused on topic modeling and document similarity
- Easy to use and optimized for large datasets
- Includes a variety of vectorization methods and models
Cons
- Limited functionality outside of topic modeling and document similarity
- No pre-trained models for NER or sentiment analysis
- Documentation can be sparse at times
NLP with NLTK
Pros
- Extensive documentation and resources
- Wide range of functionality for NLP tasks
- Includes pre-trained models for NER and sentiment analysis
Cons
- Can be slow and memory-intensive for large datasets
- Some methods are outdated or less accurate than other libraries
- Requires more setup and configuration than other libraries
NLP with SpaCy
Pros
- Fast and memory-efficient
- Includes pre-trained models for a variety of NLP tasks
- Easy to use and highly customizable
Cons
- Less documentation and resources compared to NLTK
- Limited support for languages other than English
- Customization can require more expertise and development time
Important Concepts in NLP with Spacy
- Tokenization
- Part-of-speech Tagging
- Named Entity Recognition
- Dependency Parsing
- Word Embeddings
- Text Classification
- Sentiment Analysis
- Stemming and Lemmatization
- Information Extraction
- Language Models
To Know Before You Learn NLP with Spacy?
- Basic understanding of Python programming language
- Understanding of basic NLP concepts, such as tokenization, part-of-speech tagging, and named entity recognition
- Familiarity with machine learning concepts such as supervised and unsupervised learning
- Understanding of text pre-processing techniques, such as stemming and lemmatization
- Familiarity with neural networks and deep learning concepts
- Basic understanding of data structures, such as lists, dictionaries, and arrays
- Familiarity with data visualization tools such as matplotlib and seaborn
What’s Next?
- Text classification with Spacy
- Named entity recognition with Spacy
- Sentiment analysis with Spacy
- Dependency parsing with Spacy
- Information extraction with Spacy
- Advanced techniques in NLP with Spacy
Relevant entities
| Entity | Properties |
|---|---|
| Spacy | NLP library for advanced text processing |
| Token | Individual elements of a text, such as words and punctuation marks |
| Part-of-speech | The grammatical category of a word, such as noun or verb |
| Named Entity | A specific type of entity that has a name, such as a person, organization or location |
| Dependency | The grammatical relationship between words in a sentence |
| Information extraction | The process of automatically extracting useful information from unstructured data |
Frequently Asked Questions
Text processing with Spacy.
Extracting information from unstructured text.
Linguistics, machine learning and data processing.
Scikit-learn, Pandas, and NLTK.
Tokenization, part-of-speech tagging, and named entity recognition.
Chatbots, sentiment analysis, and text classification.
Conclusion
Spacy is an incredibly powerful NLP library that can help you build intelligent language applications quickly and easily. With its speed, accuracy, and scalability, Spacy is an excellent choice for businesses and developers looking to leverage the power of natural language processing.
In this article, we’ve explored the basics of Spacy, its features, and how you can use it to solve real-world problems. Whether you’re building chatbots, analyzing social media data, or developing voice assistants, Spacy is an essential tool in your NLP toolkit.
So what are you waiting for? Start exploring the world of NLP with Spacy today and unleash the power of natural language processing!
sources
- Official Spacy documentation: https://spacy.io/
- Spacy 101 tutorial: https://spacy.io/usage/spacy-101
- Spacy tutorial on Real Python: https://realpython.com/natural-language-processing-spacy-python/
- Spacy tutorial on Analytics Vidhya: https://www.analyticsvidhya.com/blog/2019/10/how-to-build-knowledge-graph-text-using-spacy/
- Spacy tutorial on Towards Data Science: https://towardsdatascience.com/using-spacy-for-linguistic-features-in-machine-learning-c251b7ce600e
- Spacy tutorial on Medium: https://medium.com/@ageitgey/natural-language-processing-is-fun-9a0bff37854e
- Spacy tutorial on Datacamp: https://www.datacamp.com/community/tutorials/word-vector-tutorial-spacy
- Spacy tutorial on KDNuggets: https://www.kdnuggets.com/2020/06/complete-guide-entity-recognition-spacy.html
- https://www.kaggle.com/code/poonaml/text-classification-using-spacy
