
Tokenization is a fundamental process in natural language processing (NLP) that involves breaking down text into smaller units, known as tokens. These tokens are useful in many NLP tasks such as Named Entity Recognition (NER), Part-of-Speech (POS) tagging, and text classification.
Why Tokenization is important
Tokenization is important because it makes it easier to process natural language text by breaking it down into smaller, manageable pieces. This process helps to standardize the data and remove unwanted characters and words. It is a crucial step in preparing text data for machine learning models to process and interpret.
Understand Tokenization Visually
Tokenization breaks up text into individual words, phrases, or sentences.
import spacy
# Load Spacy's English language model
nlp = spacy.load('en_core_web_sm')
# Define the input text
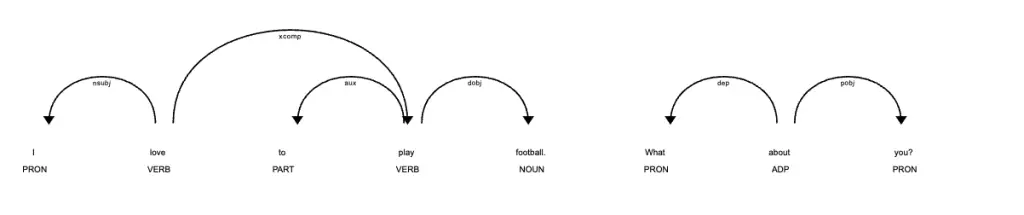
text = "I love to play football. What about you?"
# Tokenize the input text using Spacy
doc = nlp(text)
# Print each token in the input text
for token in doc:
print(token.text)
# Visualize the tokenization using Spacy's built-in visualization tool
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True)
This code will tokenize the input text “I love to play football. What about you?” using Spacy and print each token in the input text.
I
love
to
play
football
.
What
about
you
?It will also visualize the tokenization using Spacy’s built-in visualization tool, which displays a dependency parse tree.
Types of Tokenization
There are two main types of tokenization:
- word tokenization
- sentence tokenization
Word tokenization
Word tokenization involves breaking text into individual words.
In can be done in one of three ways:
- Python split() method
- NLTK word_tokenize()
- Spacy tokenizer
Tokenization with Python split() Method
When it comes to word tokenization, using split() and string tokenizer is not always reliable, especially when dealing with complex texts such as those with contractions, hyphenated words, and multiple punctuation marks.
# Word tokenization with split()
sentence = "I'm not sure if I'm ready to go."
tokens = sentence.split()
print('Tokenization with split():\n',tokens)Tokenization with split():
["I'm", 'not', 'sure', 'if', "I'm", 'ready', 'to', 'go.']Tokenization with NLTK word_tokenize()
On the other hand, word_tokenize() provided by the Natural Language Toolkit (NLTK) and spaCy’s tokenizer are more advanced and effective in tokenizing words, as they take into account the grammatical rules of the language.
For example, let’s consider the sentence “I’m not sure if I’m ready to go.” The split() method would tokenize the sentence as follows: [“I’m”, “not”, “sure”, “if”, “I’m”, “ready”, “to”, “go.”], whereas word_tokenize() would tokenize it as [“I”, “‘m”, “not”, “sure”, “if”, “I”, “‘m”, “ready”, “to”, “go”, “.”], taking into account the contractions of “I am” and preserving the punctuation.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
sentence = "I'm not sure if I'm ready to go."
# Word tokenization with nltk()
tokens = word_tokenize(sentence)
print('Tokenization with nltk:\n',tokens)Tokenization with nltk:
['I', "'m", 'not', 'sure', 'if', 'I', "'m", 'ready', 'to', 'go', '.']Tokenization with spaCy
Similarly, spaCy’s tokenizer would tokenize the sentence in a similar way to word_tokenize().
import spacy
sentence = "I'm not sure if I'm ready to go."
# Word tokenization with Spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(sentence)
tokens = [token.text for token in doc]
print('Tokenization with SpaCy:\n',tokens)
Tokenization with SpaCy:
['I', "'m", 'not', 'sure', 'if', 'I', "'m", 'ready', 'to', 'go', '.']Compare Split, NLTK and spaCy Tokenizers
Here is the full comparison:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
import spacy
# Word tokenization with split()
sentence = "I'm not sure if I'm ready to go."
tokens = sentence.split()
print('Tokenization with split():\n',tokens)
# Word tokenization with nltk()
tokens = word_tokenize(sentence)
print('Tokenization with nltk:\n',tokens)
# Word tokenization with Spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(sentence)
tokens = [token.text for token in doc]
print('Tokenization with SpaCy:\n',tokens)
Tokenization with split():
["I'm", 'not', 'sure', 'if', "I'm", 'ready', 'to', 'go.']
Tokenization with nltk:
['I', "'m", 'not', 'sure', 'if', 'I', "'m", 'ready', 'to', 'go', '.']
Tokenization with SpaCy:
['I', "'m", 'not', 'sure', 'if', 'I', "'m", 'ready', 'to', 'go', '.']Sentence tokenization
Sentence tokenization involves breaking text into individual sentences.
When it comes to sentence tokenization in Python, there are several popular options to choose from. One approach is to use the split() method from the built-in string module. Another option is to use the sent_tokenize() method from the Natural Language Toolkit (nltk) library. Finally, there’s the spaCy library, which provides its own built-in tokenizer.
Here’s an example of how each of these approaches can be used to tokenize a paragraph of text:
import string
import nltk
import spacy
# Example text
text = "This is a sentence. This is another sentence. And this is a third sentence."
# Tokenize with string.split()
sentences = text.split(". ")
print('Tokenization with split():\n', sentences)
# Tokenize with nltk.sent_tokenize()
sentences = nltk.sent_tokenize(text)
print('Tokenization with nltk:\n', sentences)
# Tokenize with spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
sentences = [sent.text for sent in doc.sents]
print('Tokenization with SpaCy:\n', sentences)
In this example, we first define a paragraph of text as our input. We then tokenize the text into sentences using split(), sent_tokenize(), and spaCy’s built-in tokenizer.
The split() method simply splits the input text on every occurrence of the period followed by a space (i.e., “. “). This can work well for simple cases, but it may fail to properly tokenize more complex text (e.g., text with abbreviations or numbers).
The sent_tokenize() method from nltk uses a more sophisticated approach that takes into account common abbreviations and other sentence boundary markers. This can result in more accurate tokenization, but it may also be slower and more resource-intensive.
Finally, spaCy’s built-in tokenizer is designed to handle a wide range of input text, including text with complex grammatical structures and named entities. This can make it a powerful tool for text analysis, but it may also require more processing power and memory than other options.
Tokenization with split():
['This is a sentence', 'This is another sentence', 'And this is a third sentence.']
Tokenization with nltk:
['This is a sentence.', 'This is another sentence.', 'And this is a third sentence.']
Tokenization with SpaCy:
['This is a sentence.', 'This is another sentence.', 'And this is a third sentence.']Challenges with Tokenization
Tokenization can be challenging because of the complexity of natural language. Languages like English can have compound words or contractions that are difficult to split into individual tokens. Additionally, some languages may not have clear boundaries between words or sentences. These challenges can impact the accuracy of NLP models.
Tokenization Libraries
There are several libraries in Python that provide tokenization functionality, including the Natural Language Toolkit (NLTK), spaCy, and Stanford CoreNLP. These libraries offer customizable tokenization options to fit specific use cases.
Useful Python Libraries for Tokenization
- NLTK: word_tokenize(), sent_tokenize()
- spaCy: tokenizer
- scikit-learn: CountVectorizer(), TfidfVectorizer()
Datasets useful for Tokenization
NLTK Corpora
NLTK (Natural Language Toolkit) is a popular Python library for working with human language data. It includes several built-in corpora that can be used to learn about tokenization, including the Gutenberg Corpus, Brown Corpus, and Reuters Corpus. To load the Gutenberg Corpus in Python:
import nltk
nltk.download('gutenberg')
from nltk.corpus import gutenberg
# Load the text of Jane Austen's Emma
emma = gutenberg.raw('austen-emma.txt')
IMDb Movie Reviews Dataset
The IMDb Movie Reviews Dataset contains 50,000 movie reviews for training and testing natural language processing models. The dataset is often used to build sentiment analysis models, but it can also be used to learn about tokenization.
Important Concepts in Tokenization
- Text preprocessing
- Linguistics basics
- Regular expressions
- Stop words
- Word frequency
- N-grams
- Contextual information
To Know Before You Learn Tokenization?
- Basic understanding of natural language processing (NLP)
- Knowledge of regular expressions
- Familiarity with programming languages such as Python or Java
- Understanding of different types of data formats such as text, HTML, and XML
- Understanding of different types of text data such as social media posts, web pages, and emails
What’s Next?
- Part-of-speech (POS) tagging
- Named entity recognition (NER)
- Text classification
- Sentiment analysis
- Dependency parsing
Frequently Asked Questions
Tokenization is splitting a sentence or a document into smaller units called tokens.
Tokenization is important in natural language processing to transform text into a format that can be easily analyzed and processed by machine learning algorithms.
The most common methods for tokenization include using space as a delimiter, regular expressions, and machine learning-based tokenization.
Word tokenization splits text into words, while sentence tokenization splits text into sentences.
Tokenization helps in text analysis by simplifying the text into its basic elements and enabling the analysis of each word or sentence individually.
Challenges associated with tokenization include handling ambiguous words, recognizing and removing stop words, and dealing with language-specific nuances and rules.
Relevant Entities
| Entity | Properties |
|---|---|
| Token | Text, Position, Part-of-speech, NER, etc. |
| Corpus | Collection of text documents |
| Stopwords | Commonly occurring words that can be ignored |
| Lemmatization | Process of grouping together inflected forms of a word to be analyzed as a single item |
| Stemming | Process of reducing words to their base or root form |
| Tokenizer | Tool that splits text into tokens or words |
Conclusion
Tokenization is a crucial step in natural language processing that involves breaking down text into smaller, manageable pieces.
It is a necessary step in preparing text data for machine learning models to process and interpret. With the advent of powerful NLP libraries like spaCy and NLTK, tokenization has become an easier task. However, challenges such as compound words or unclear boundaries between words and sentences still exist. Despite these challenges, tokenization remains a vital process in the field of NLP.
sources
- https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/
- https://nlp.stanford.edu/IR-book/html/htmledition/tokenization-1.html
- https://towardsdatascience.com/tokenization-for-natural-language-processing-a654a284bf53
- https://towardsdatascience.com/tokenization-in-nlp-8f23a278f409
- https://machinelearningmastery.com/prepare-text-data-machine-learning-scikit-learn/
- “Python for Data Science Handbook” book by Jake VanderPlas. Chapter 5 covers tokenization.
