
Natural Language Processing (NLP) is a game-changing field that unlocks the potential of machines to understand human language. Gensim is a powerful tool that makes it possible to process and analyze large amounts of text data.
In this article, we’ll explore the amazing capabilities of NLP with Gensim, and how it can revolutionize the way we interact with language.
Here is an example of what you can create with Gensim.
What is NLP
NLP, or Natural Language Processing, is a technology that allows machines to understand human language. This is a critical step towards creating machines that can communicate with humans in a more natural and intuitive way. NLP can be used for a wide range of applications, from sentiment analysis and topic modeling to machine translation and chatbots. With NLP, we can analyze and process large amounts of text data quickly and accurately.
What is Gensim
Gensim is an open-source library that enables developers to work with NLP more easily.
With Gensim, you can create models that can process large amounts of text data and extract relevant information from it. Gensim supports a wide range of algorithms, including Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and Word2Vec. These algorithms can be used for a variety of tasks, such as topic modeling, semantic analysis, and similarity detection.
Installing Gensim in Python
To install Gensim, you can use pip by running the following command in your terminal or command prompt:
pip install gensim
pip install pyLDAvisInstalling Gensim Datasets
To install and load Gensim datasets, you need to use the downloader.load() method.
Here is and example of how to load the “text8” gensim datasets.
import gensim.downloader as api
# Load the dataset
dataset = api.load('text8')
Show Information About a Gensim Dataset
api.info('text8'){'num_records': 1701,
'record_format': 'list of str (tokens)',
'file_size': 33182058,
'reader_code': 'https://github.com/RaRe-Technologies/gensim-data/releases/download/text8/__init__.py',
'license': 'not found',
'description': 'First 100,000,000 bytes of plain text from Wikipedia. Used for testing purposes; see wiki-english-* for proper full Wikipedia datasets.',
'checksum': '68799af40b6bda07dfa47a32612e5364',
'file_name': 'text8.gz',
'read_more': ['http://mattmahoney.net/dc/textdata.html'],
'parts': 1}Gensim Dictionary
The gensim.corpora.Dictionary class is used to create a dictionary from a corpus of text. The dictionary contains a mapping of words to unique integer ids. The Dictionary class can be initialized with a list of documents (corpus), where each document is a list of words. Once the dictionary is created, it can be used to convert documents into vectors of integers that can be used for training machine learning models.
from gensim.corpora.dictionary import Dictionary
# Example corpus
corpus = [['machine', 'learning', 'is', 'fun'], ['python', 'is', 'a', 'popular', 'language']]
# Create a gensim dictionary
dictionary = Dictionary(corpus)
# Print the dictionary
print(dictionary.token2id)
In the example code above, the Dictionary class is used to create a dictionary from a corpus of two documents. The token2id attribute of the dictionary object is a dictionary containing the mapping of words to unique integer ids. The output of the code would be:
{'fun': 0, 'is': 1, 'learning': 2, 'machine': 3, 'a': 4, 'language': 5, 'popular': 6, 'python': 7}Create a Bag-of-Words with Gensim
import gensim.downloader as api
from gensim import corpora
# Load the dataset
dataset = api.load('text8')
# Extract the text data from the dataset
text_data = [doc for doc in dataset]
# Create a dictionary object that maps the cleaned text data to unique IDs
dictionary = corpora.Dictionary(text_data)
# Create a bag-of-words representation of the text data
bow_corpus = [dictionary.doc2bow(doc) for doc in text_data]
Text Preprocessing with Gensim
Gensim is a topic modelling library and does not have a preprocessing tools as good as what Spacy or NLTK have.
However, we can use the gensim.utils.simple_preprocess() function to tokenize text into a list of lowercase tokens.
from gensim.utils import simple_preprocess
text = "This is an example sentence for tokenization using Gensim."
tokens = simple_preprocess(text)
print(tokens)
['this', 'is', 'an', 'example', 'sentence', 'for', 'tokenization', 'using', 'gensim']Topic Modeling with Gensim
One of the most powerful features of Gensim is its ability to perform topic modeling. Topic modeling is the process of identifying the topics that are present in a large amount of text data.
Gensim’s LDA algorithm is particularly useful for topic modeling.
With LDA, you can identify the topics that are most prevalent in a given dataset, and you can also identify the words that are most closely associated with each topic.
import gensim.downloader as api
from gensim import corpora, models
from gensim.models import CoherenceModel
import pyLDAvis.gensim
# Load the dataset
dataset = api.load('text8')
# Extract the text data from the dataset
text_data = [doc for doc in dataset]
# Create a dictionary object that maps the cleaned text data to unique IDs
dictionary = corpora.Dictionary(text_data)
# Create a bag-of-words representation of the text data
bow_corpus = [dictionary.doc2bow(doc) for doc in text_data]
# Train a topic model using the bag-of-words representation of the text data
num_topics = 10
lda_model = models.LdaModel(bow_corpus, num_topics=num_topics, id2word=dictionary)
# Evaluate the topic model and determine the optimal number of topics
coherence_model_lda = CoherenceModel(model=lda_model, texts=text_data, dictionary=dictionary, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)
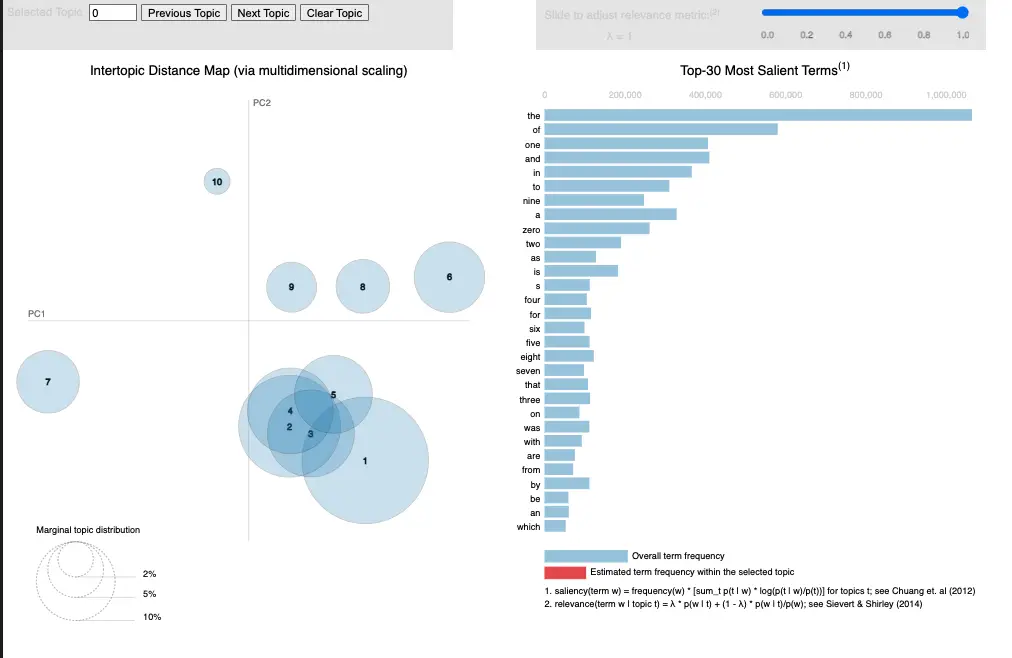
# Visualize the topic model using pyLDAvis
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, bow_corpus, dictionary)
vis
Note: This code assumes that you have already installed the Gensim library and the pre-existing dataset that you are using. Additionally, the code may need to be customized based on your specific use case, such as adjusting the number of topics or changing the coherence metric.
Please make sure to read the Gensim documentation and other relevant resources to ensure that you are using the library effectively and appropriately.
Semantic Analysis with Gensim
Semantic analysis is the process of extracting meaning from text data. Gensim’s Word2Vec algorithm is particularly useful for semantic analysis. Word2Vec can identify the meaning of words based on their context in a sentence.
This allows you to perform tasks such as word embedding, which is the process of representing words as numerical vectors.
import gensim.downloader as api
from gensim import corpora, models
import numpy as np
import matplotlib.pyplot as plt
# Load the dataset
dataset = api.load('text8')
# Extract the text data from the dataset
text_data = [doc for doc in dataset]
# Create a dictionary object that maps the cleaned text data to unique IDs
dictionary = corpora.Dictionary(text_data)
# Create a bag-of-words representation of the text data
bow_corpus = [dictionary.doc2bow(doc) for doc in text_data]
# Train a semantic analysis model using the bag-of-words representation of the text data
lsa_model = models.LsiModel(bow_corpus, id2word=dictionary, num_topics=10)
# Use the semantic analysis model to get the most relevant topics for a given document
doc_num = 100
doc = text_data[doc_num]
doc_bow = bow_corpus[doc_num]
doc_lsa = lsa_model[doc_bow]
doc_lsa = sorted(doc_lsa, key=lambda x: x[1], reverse=True)
# Visualize the most relevant topics for the given document
labels, values = zip(*doc_lsa)
plt.bar(np.arange(len(labels)), values, align='center', alpha=0.5)
plt.xticks(np.arange(len(labels)), labels)
plt.ylabel('LSA Value')
plt.title('LSA Topics for Document {}'.format(doc_num))
plt.show()

Similarity Detection with Gensim
Another powerful feature of Gensim is its ability to perform similarity detection. Similarity detection is the process of identifying how similar two pieces of text are to each other. Gensim’s similarity algorithms can be used to identify similarities between documents, sentences, and even individual words. This can be useful for a wide range of applications, such as plagiarism detection and content recommendation.
import gensim
import gensim.downloader as api
from gensim import corpora, models, similarities
import numpy as np
import matplotlib.pyplot as plt
# Load the dataset
dataset = api.load('text8')
# Extract the text data from the dataset
text_data = [doc for doc in dataset]
# Create a dictionary object that maps the cleaned text data to unique IDs
dictionary = corpora.Dictionary(text_data)
# Create a bag-of-words representation of the text data
bow_corpus = [dictionary.doc2bow(doc) for doc in text_data]
# Train a semantic analysis model using the bag-of-words representation of the text data
lsa_model = models.LsiModel(bow_corpus, id2word=dictionary, num_topics=10)
# Create an index for the bag-of-words corpus
index = similarities.MatrixSimilarity(lsa_model[bow_corpus])
# Use the index to calculate the similarity of a given document to all other documents in the dataset
doc_num = 100
doc = text_data[doc_num]
doc_bow = bow_corpus[doc_num]
doc_lsa = lsa_model[doc_bow]
sims = index[doc_lsa]
# Sort the similarities in descending order
sims = sorted(enumerate(sims), key=lambda item: -item[1])
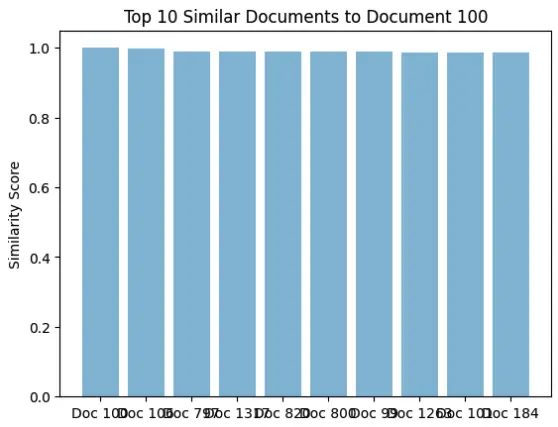
# Visualize the top similar documents for the given document
top_n = 10
similar_docs = [text_data[i] for i, s in sims[:top_n]]
labels = ['Doc {}'.format(i) for i, s in sims[:top_n]]
values = [s for i, s in sims[:top_n]]
plt.bar(np.arange(len(labels)), values, align='center', alpha=0.5)
plt.xticks(np.arange(len(labels)), labels)
plt.ylabel('Similarity Score')
plt.title('Top {} Similar Documents to Document {}'.format(top_n, doc_num))
plt.show()
Word Embeddings in Gensim
Here’s an example of how to generate word embeddings using the Gensim library in Python:
from gensim.models import Word2Vec
sentences = [["the", "cat", "sat", "on", "the", "mat"],
["the", "dog", "ran", "in", "the", "park"],
["the", "bird", "sang", "in", "the", "tree"]]
model = Word2Vec(sentences, vector_size=10, window=3, min_count=1, workers=4)
# Get the vector representation of a word
vector = model.wv['cat']
print(vector)This code generates word embeddings using the Word2Vec algorithm on a small corpus of three sentences. The resulting vectors have a dimensionality of 10. We can obtain the vector representation of a word by using the wv attribute of the trained Word2Vec model.
[-0.00410223 -0.08368949 -0.05600012 0.07104538 0.0335254 0.0722567
0.06800248 0.07530741 -0.03789154 -0.00561806]Important Concepts in NLP with Gensim
- Latent Semantic Analysis (LSA)
- Latent Dirichlet Allocation (LDA)
- Word2Vec
- Topic Modeling
- Semantic Analysis
- Similarity Detection
- Natural Language Processing (NLP)
- Machine Learning (ML)
- Text Data Preprocessing
- Bag-of-Words Model
- TF-IDF Model
- Corpus
- Tokenization
- Stop Words
- Stemming
- Lemmatization
- Named Entity Recognition (NER)
- Sentiment Analysis
- Part-of-Speech (POS) Tagging
- Language Models
NLP Python Tutorials
- NLP with Gensim
- NLP with NLTK
- NLP with SpaCy
- NLP with TextBlob
- NLP with Scikit-learn
NLTK VS spaCy VS Gensim
NLP with Gensim
Pros
- Focused on topic modeling and document similarity
- Easy to use and optimized for large datasets
- Includes a variety of vectorization methods and models
Cons
- Limited functionality outside of topic modeling and document similarity
- No pre-trained models for NER or sentiment analysis
- Documentation can be sparse at times
NLP with NLTK
Pros
- Extensive documentation and resources
- Wide range of functionality for NLP tasks
- Includes pre-trained models for NER and sentiment analysis
Cons
- Can be slow and memory-intensive for large datasets
- Some methods are outdated or less accurate than other libraries
- Requires more setup and configuration than other libraries
NLP with SpaCy
Pros
- Fast and memory-efficient
- Includes pre-trained models for a variety of NLP tasks
- Easy to use and highly customizable
Cons
- Less documentation and resources compared to NLTK
- Limited support for languages other than English
- Customization can require more expertise and development time
Datasets useful for NLP with Gensim
Text8
import gensim.downloader as api
# Load the dataset
dataset = api.load('text8')
# Extract the text data from the dataset
text_data = [doc for doc in dataset]Quora Duplicate Questions
import gensim.downloader as api
quora = api.load("quora-duplicate-questions") # load extracted Wikipedia dump, around 6 Gb
for article in quora: # iterate over all wiki script
print(article)
break
20 Newsgroup
import gensim.downloader as api
data = api.load("20-newsgroups") # load extracted Wikipedia dump, around 6 Gb
for x in data: # iterate over all wiki script
print(x)
breakFake News
import gensim.downloader as api
data = api.load("fake-news")
for x in data:
print(x)
breakRelevant Entities
| Entity | Properties |
|---|---|
| Gensim | Open-source library, used for NLP tasks such as topic modeling, semantic analysis, and similarity detection |
| Latent Semantic Analysis (LSA) | An unsupervised ML technique used to discover the underlying topics in a corpus |
| Latent Dirichlet Allocation (LDA) | An unsupervised ML technique used for topic modeling, it assumes that each document contains multiple topics, and each topic contains a set of words |
| Word2Vec | A neural network-based model used for semantic analysis, it learns the meaning of words based on their context in a sentence |
| Corpus | A collection of text documents used for NLP tasks |
| Tokenization | The process of splitting a text document into individual words or tokens |
| Stop Words | Common words such as “the”, “and”, and “is” that are removed from text data during preprocessing to improve NLP performance |
Frequently Asked Questions
Open-source NLP library.
Unsupervised ML for topic modeling.
Neural network for semantic analysis.
Unsupervised ML for topic modeling.
Collection of text documents.
Splitting text into words.
Conclusion
In conclusion, NLP with Gensim is a powerful combination that has the potential to revolutionize the way we interact with language. With Gensim, you can perform tasks such as topic modeling, semantic analysis, and similarity detection more easily and accurately than ever before. If you’re interested in exploring the amazing capabilities of NLP, Gensim is a tool you should definitely consider. So why not give it a try and see what you can achieve?
